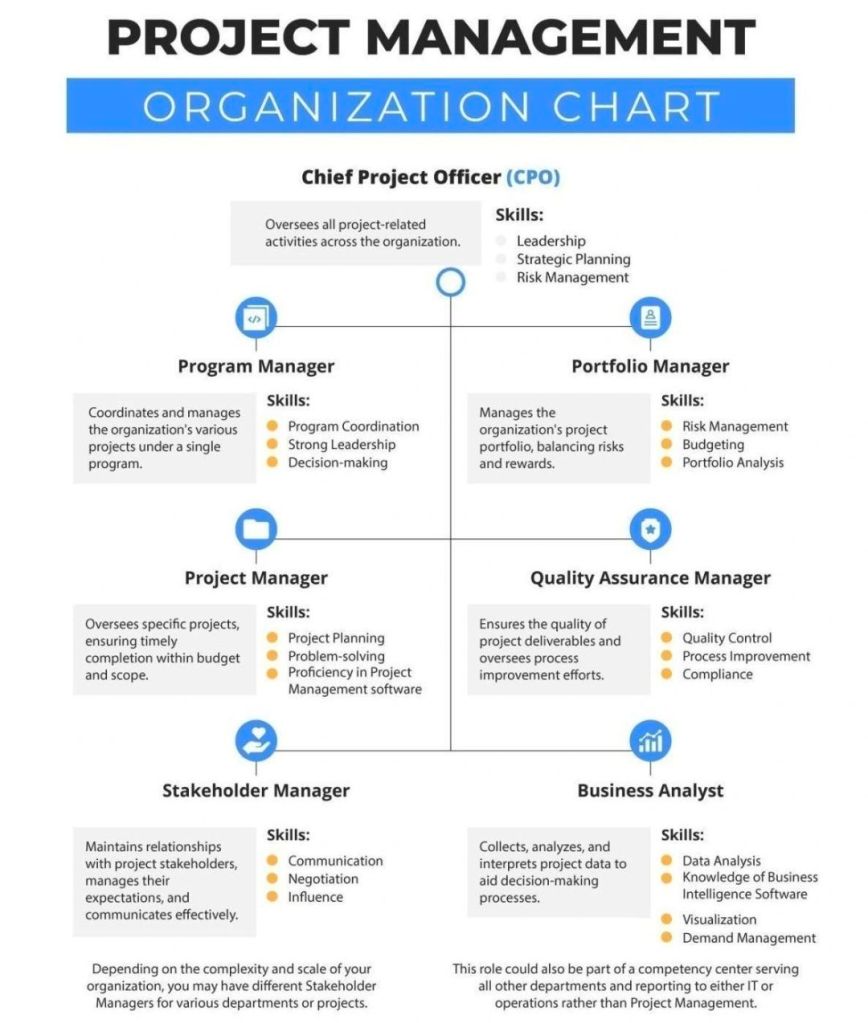
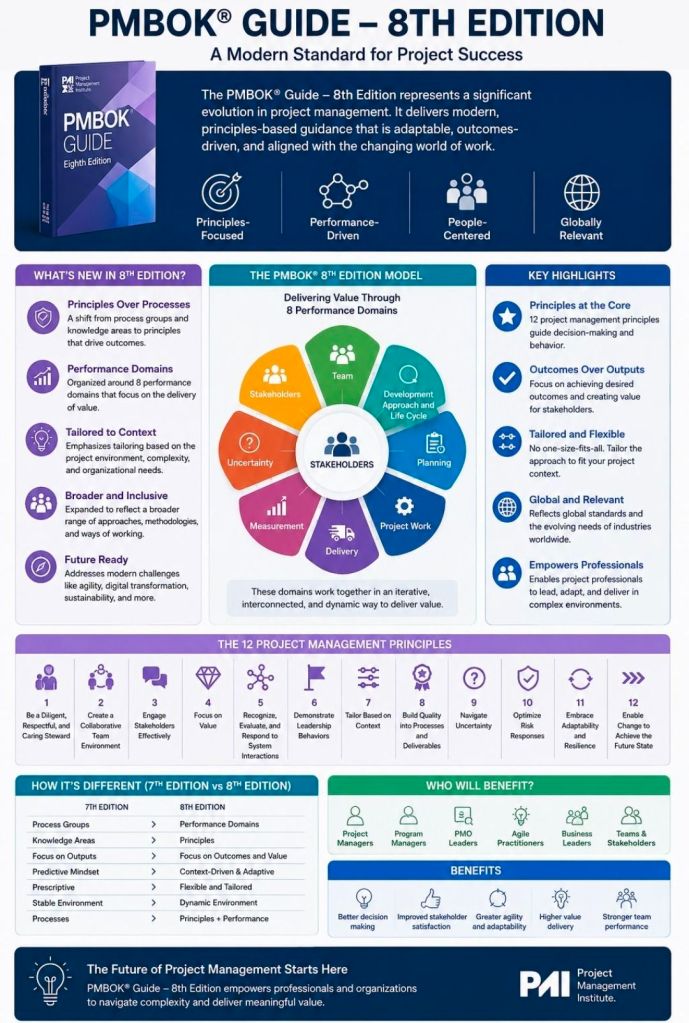
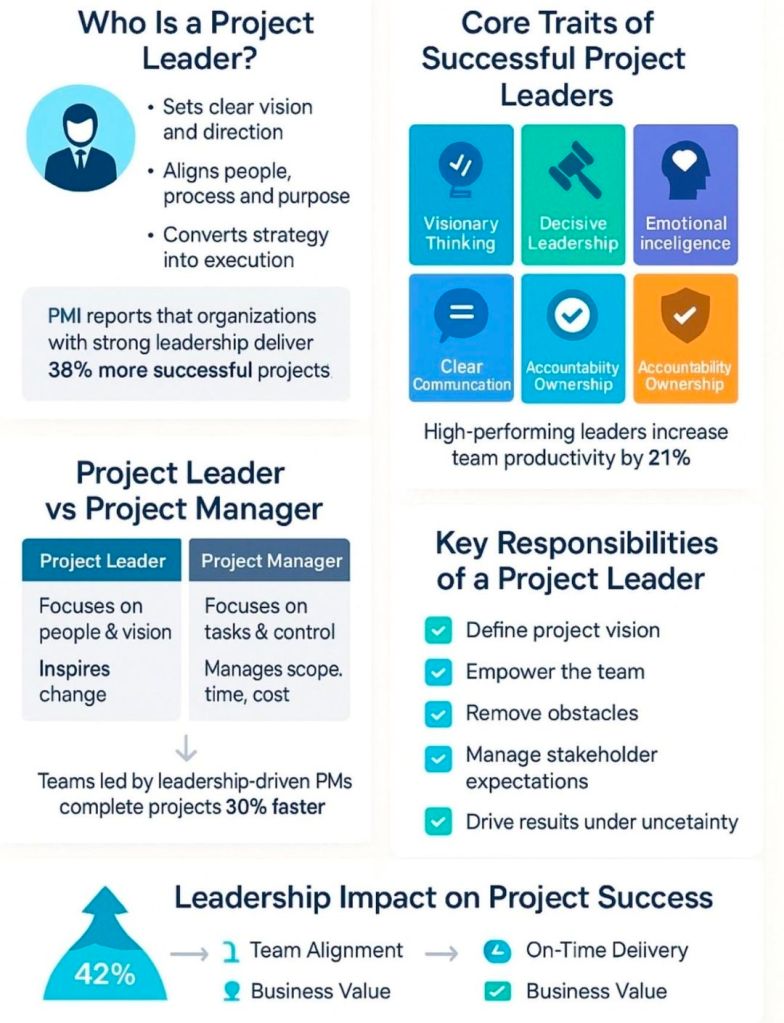
Stewardship: Act with integrity, care, trustworthiness, and strict compliance to responsibly manage assets, finance, and social impacts.
Team: Foster a highly collaborative, respectful, and trusting project team environment to optimize productivity and collective learning.
Stakeholders: Engage proactively and effectively with all impacted individuals or groups to advance value delivery and counter opposition.
Value: Maintain a continuous focus on outcomes and intended business benefits rather than tracking empty operational outputs.
Systems Thinking: Evaluate and respond dynamically to internal and external system interactions to recognize how different project parts interconnect.
Leadership: Demonstrate adaptable, ethical leadership behaviors across all team members, regardless of formal titles or authority status.
Tailoring: Adapt the management framework iteratively based on context, unique project objectives, scope, governance, and environmental constraints.
Quality: Embed rigorous evaluation and acceptance criteria directly into project processes and deliverables to satisfy required expectations.
Complexity: Continuously identify, evaluate, and navigate project complexities arising from erratic human behaviors, system interactions, or ambiguity.
Risk: Optimize response mechanisms to systematically mitigate negative threats while proactively capturing positive project opportunities.
Adaptability & Resilience: Build structural flexibility into plans to rapidly recover from sudden setbacks and accommodate shifting environments.
Change: Prepare and support stakeholders for the targeted future state to avoid change fatigue and successfully implement new behaviors.
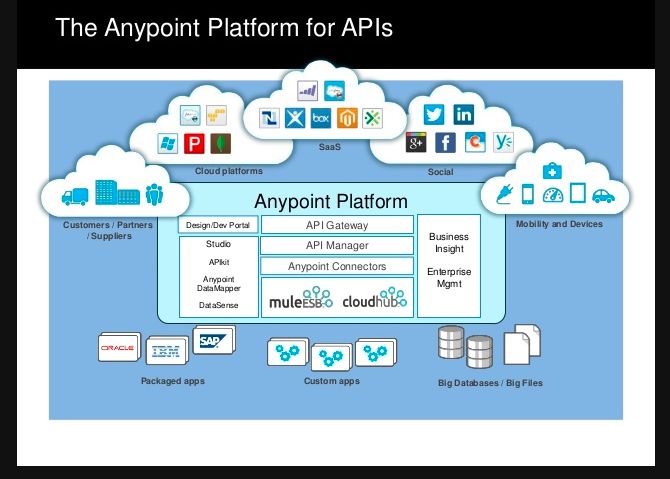
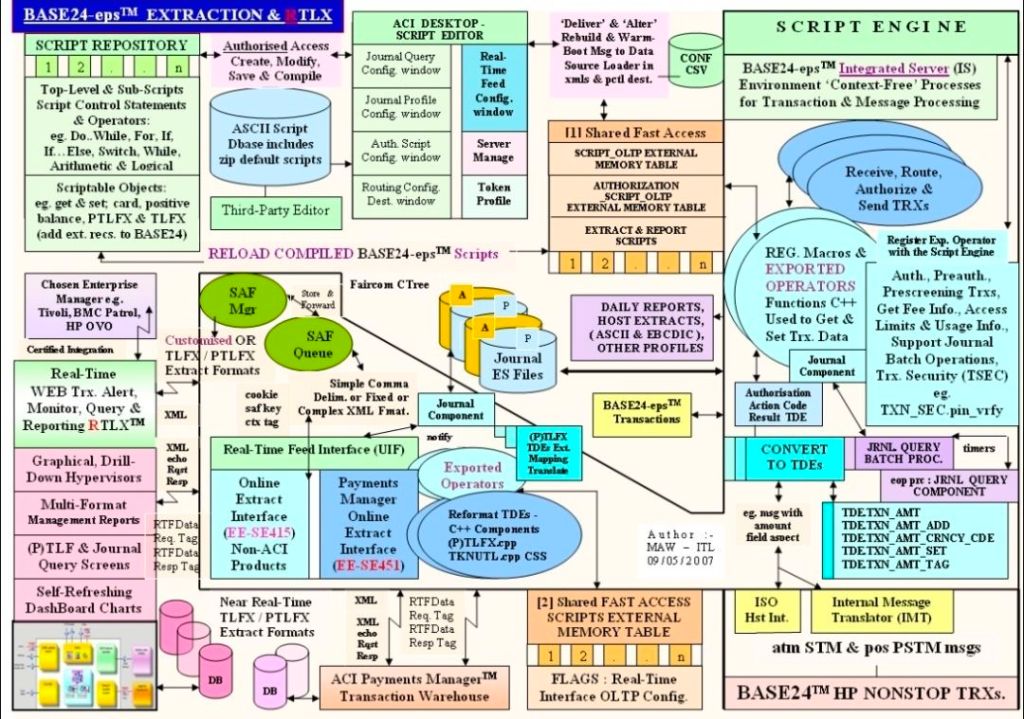
Salesforce MuleSoft is an industry-leading Integration Platform as a Service (iPaaS) and automation solution that enables organizations to securely connect data, applications, and devices across hybrid cloud and on-premises environments. Instead of relying on rigid, custom-coded point-to-point connections, MuleSoft uses an API-led connectivity approach. This methodology treats every system connection as a modular, reusable building block (System, Process, and Experience APIs).
October 2018 – June 2019, was assigned as a Delivery Manager at MuleSoft
Core Capabilities
Anypoint Platform: The flagship product covering the entire lifecycle of API design, testing, deployment, governance, and monitoring.
MuleSoft Automation: A suite combining Composer (no-code integration for business teams) and Robotic Process Automation (RPA) to automate workflows across legacy and modern platforms.
Salesforce Ecosystem Synergy: Acts as the data integration engine for Salesforce Customer 360, bringing siloed third-party systems together to establish a single customer view.
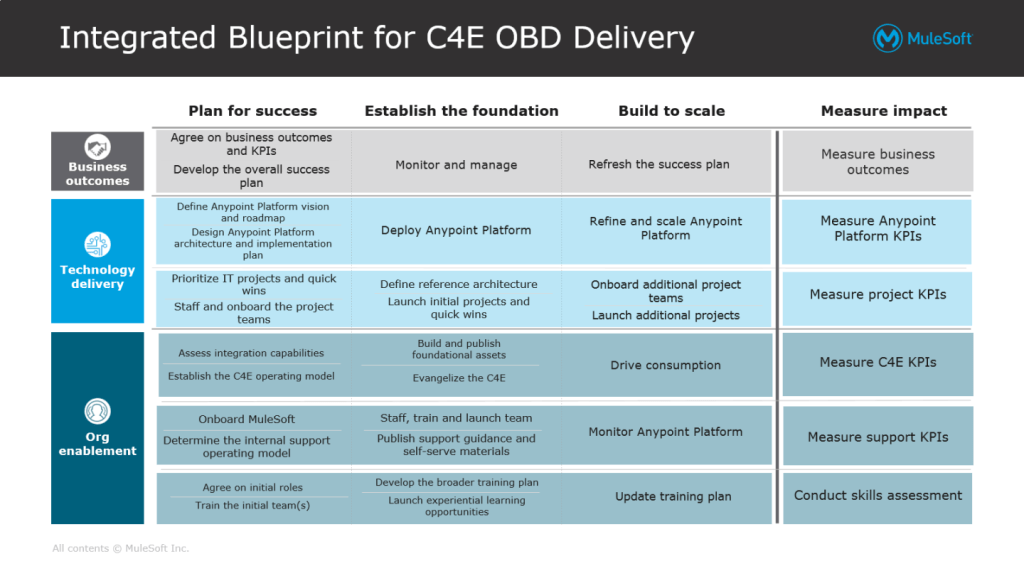
Outcome Based Delivery (OBD) Model, C4E, Center for Excellence
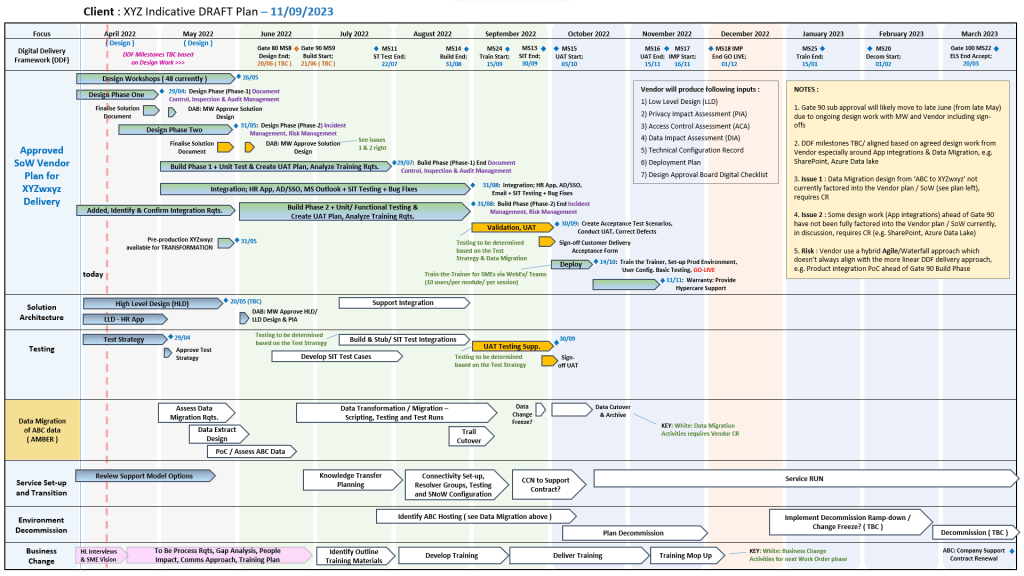
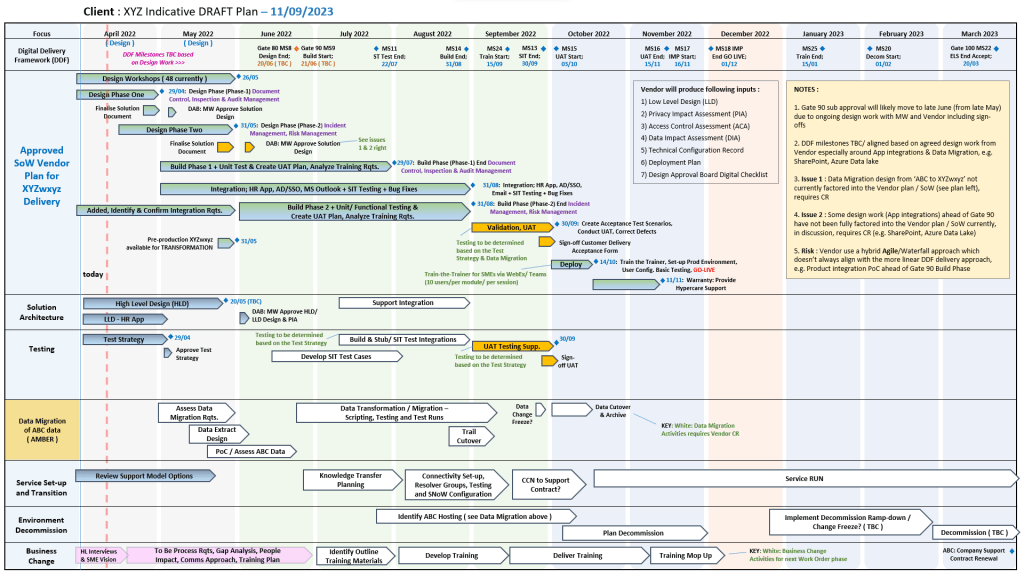
Detailed Timeline Breakdown
The evolution of MuleSoft spans four distinct eras, progressing from a niche open-source project to an enterprise integration powerhouse, culminating in its massive acquisition and expansion under Salesforce.
Era 1: The Open-Source Roots (2003 – 2008)
This era focused on addressing the tedious “donkey work” of custom data integration through open-source software.
2003: Developer Ross Mason creates the Mule open-source project. He writes an architecture framework to move away from rigid, proprietary integration infrastructure. The project name stems from the literal “mule work” or drudgery of writing point-to-point connections.
2006: Ross Mason and Dave Rosenberg co-found MuleSource in San Francisco. The company is built to commercialize the open-source Mule Enterprise Service Bus (ESB) project.
2007: Lightspeed Venture Partners leads a Series A funding round to back the growing open-source platform.
2008: The company expands its product landscape by focusing on developer adoption and expanding core enterprise middleware features.
Era 2: Cloud Transition and iPaaS Transformation (2009 – 2016)
During this era, the company pivoted to a subscription-based software-as-a-service model, targeting cloud applications and APIs.
2009: The company officially changes its name from MuleSource to MuleSoft. Greg Schott is hired as CEO to restructure the business, transitioning from a pure open-source model to a hybrid commercial enterprise subscription model.
2010: The development of dedicated cloud tools kicks off, responding to a massive industry shift from on-premises systems toward software-as-a-service (SaaS) applications.
2012: MuleSoft launches CloudHub, the industry’s first true multi-tenant Integration Platform as a Service (iPaaS).
2013: MuleSoft acquires ProgrammableWeb, the leading repository for web application programming interfaces (APIs), positioning itself as the voice of the emerging API economy.
2014: The company officially rolls out the Anypoint Platform, a unified product suite designed to dismantle the barriers between data applications, SaaS platforms, and APIs.
2015: MuleSoft secures a $128 million funding round led by New Enterprise Associates, with Salesforce Ventures participating as a strategic investor. Revenue breaks past the $100 million mark.
2016: The enterprise focus shifts entirely toward championing API-led connectivity over standard enterprise service bus middleware architectures.
Era 3: IPO and the Salesforce Acquisition (2017 – 2018)
The era defined by rapid financial maturation and a landmark enterprise SaaS consolidation.
2017: MuleSoft launches its Initial Public Offering (IPO) on the New York Stock Exchange under the ticker symbol MULE, valuing the business at over $1.5 billion on its first day of trading.
2018 (March): Salesforce announces a definitive agreement to acquire MuleSoft for an enterprise value of approximately $6.5 billion, making it Salesforce’s largest acquisition up to that point.
2018 (May): Salesforce completes the acquisition. MuleSoft is positioned to power the new Salesforce Integration Cloud to unlock legacy and external database silos for CRM clients.
Era 4: Modern Era—Automation and Unified Customer 360 (2019 – Present)
This era represents the deep technological coupling of MuleSoft with cloud architecture, AI, and low-code applications.
2019: Salesforce shifts strategy, abandoning the “Integration Cloud” branding to lean heavily on the trusted MuleSoft brand. The technology is deeply embedded directly into core platforms like Sales and Service Clouds.
2020: MuleSoft updates its core data engine engine with Mule 4, optimizing performance, reducing custom script overhead, and easing API lifecycle management workflows.
2021: The brand releases MuleSoft Composer, a click-based, no-code application integrated directly inside the Salesforce user interface, enabling business users to connect systems without relying on IT engineers.
2022: Salesforce expands MuleSoft’s reach beyond APIs by acquiring Servicetrace and launching MuleSoft RPA, building a comprehensive hyper-automation ecosystem alongside Composer.
2023–2024: MuleSoft adapts to the AI revolution by releasing Anypoint Code Builder and embedding Einstein AI into the workflow. Developers use natural language prompts to automatically generate integration flows and API designs.
2025–2026: MuleSoft is fully integrated as a core architectural foundation for Salesforce Data Cloud and Agentforce. It serves as the primary system of connectivity to securely feed legacy, real-time enterprise data into autonomous AI agents.
Salesforce MuleSoft Overview & Development Timeline
1. Welcome Salesforce, London Office2. Welcome Salesforce, London Office (external)
The Critical Path Method (CPM) is a project management algorithm used to identify the longest sequence of dependent tasks required to complete a project. It establishes the shortest possible project duration and highlights the “critical” activities that cannot be delayed without extending the entire project’s deadline.
How the Critical Path Works
CPM relies on finding the path through your project’s workflow that takes the most time from start to finish.
Critical Activities: Tasks on the critical path have zero “float” (or slack), meaning any delay directly impacts the final delivery date.
Non-Critical Activities: Other task sequences may have buffer time, allowing them to be delayed without throwing off the main project timeline.
Steps to Calculate the Critical Path
Identify Tasks: Break the project down into individual activities (often using a Work Breakdown Structure).
Determine Dependencies: Map out which tasks must happen before others can begin.
Estimate Durations: Assign a realistic time frame for completing each task.
Draw a Network Diagram: Create a flowchart visually connecting tasks with arrows to illustrate the sequence.
Analyze the Paths: Calculate the total duration for every possible sequence of tasks. The longest sequence is your critical path.
Key Terminology
Float (Slack): The amount of time a task can be delayed without causing a delay to subsequent tasks or the overall project.
Forward Pass: A calculation used to find the Earliest Start and Earliest Finish times for each task.
Backward Pass: A calculation used to find the Latest Start and Latest Finish times for each task before the project is delayed.
When and Why to Use It
Project managers use CPM during the planning phase to build realistic schedules and set clear baselines. It is highly beneficial for complex, predictable projects like construction or software rollouts, where many tasks rely on the completion of previous ones.
By knowing exactly which tasks control your timeline, you can prioritize resources, prevent bottlenecks, and use “fast-tracking” (doing tasks in parallel) if you need to compress a timeline.
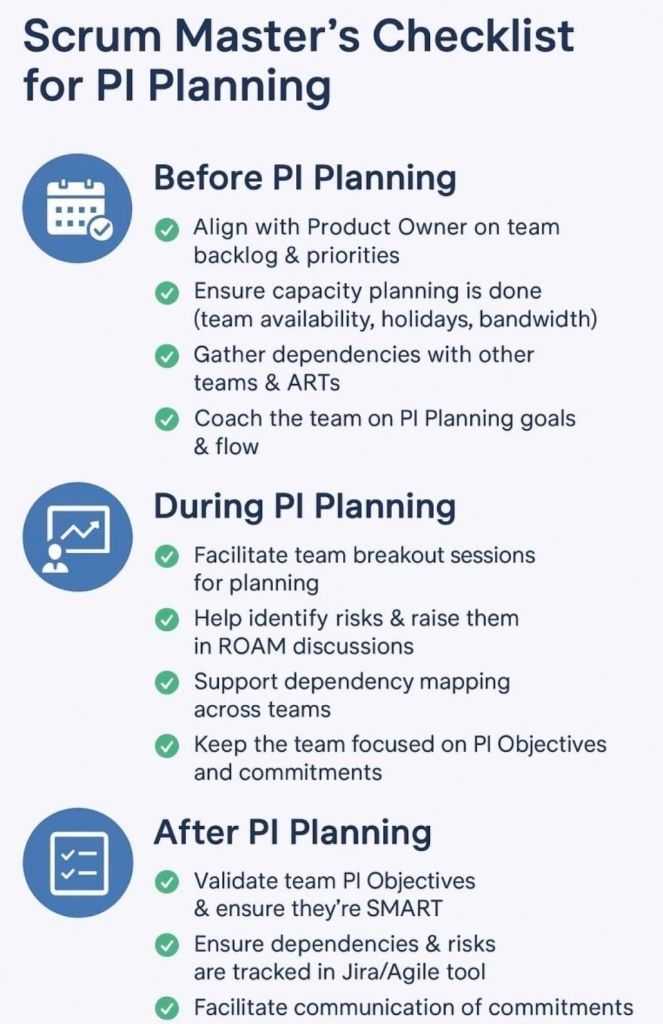
Agile Scrum Master’s Checklist for Program Increment
An Agile Scrum Master’s checklist for a Program Increment (PI)ensures your team is aligned, dependencies are resolved, and a realistic delivery plan is established for the upcoming 8–12 weeks of work. As a facilitator and coach, you support the team across three core phases: Pre-PI Planning, During PI Planning Events, and Post-PI Execution.
Here is a comprehensive checklist structured across the lifecycle of a Program Increment.
📅 Phase 1: Pre-PI Planning Readiness
Establish Sprint Cadence: Define exact start/end dates for every sprint within the upcoming PI.
Calculate Team Capacity: Factor in vacations, public holidays, corporate events, and historic team velocity.
Refine the Backlog: Collaborate with the Product Owner to ensure top features meet the Definition of Ready (DoR).
Encourage Feature Decomposition: Guide developers to begin breaking down high-priority features into draft user stories.
Prepare Digital Tooling: Set up virtual whiteboards like Miro or MURAL, and structure project boards in systems like Jira.
Align Engineering Standards: Review architectural patterns with system architects to prevent technical blockers.
🛠️ Phase 2: During the PI Planning Event
Day 1 Breakout Management: Facilitate your team’s breakdown of features into actionable, estimated sprint user stories.
Map Dependencies: Identify files, data, or logic needed from external teams and link them on the program board.
Draft PI Objectives: Help the team write clear, outcome-oriented, and SMART goals based on their planned work.
Surface Program Risks: Collaboratively categorize all technical or resource hurdles using the ROAM framework (Resolved, Owned, Accepted, Mitigated).
Day 2 Plan Finalization: Ensure uncommitted objectives are preserved for high-risk items requiring external prerequisites.
Conduct Confidence Votes: Run an anonymous digital vote to gauge psychological safety and realistic alignment before final team commitment.
🚀 Phase 3: Post-PI & Execution Tracking
Sync the Agile Tooling: Move sticky notes and analog mappings directly into active Jira epics or tracking backlogs.
Establish Sprint Tracking: Distribute automated calendar sequences for recurring Daily Scrums, Sprint Plannings, and Sprint Reviews.
Monitor Cross-Team Risks: Attend standard Scrum of Scrums (SoS) meetings to report on blockers and coordinate incoming dependency tracks.
Protect the WIP Limits: Enforce explicitly defined work-in-progress (WIP) boundaries to prevent team burnout over mid-increment changes.
Inspect and Adapt (I&A): Facilitate the final evaluation comparing actual value delivered against initial PI targets to feed process enhancements back into the train.
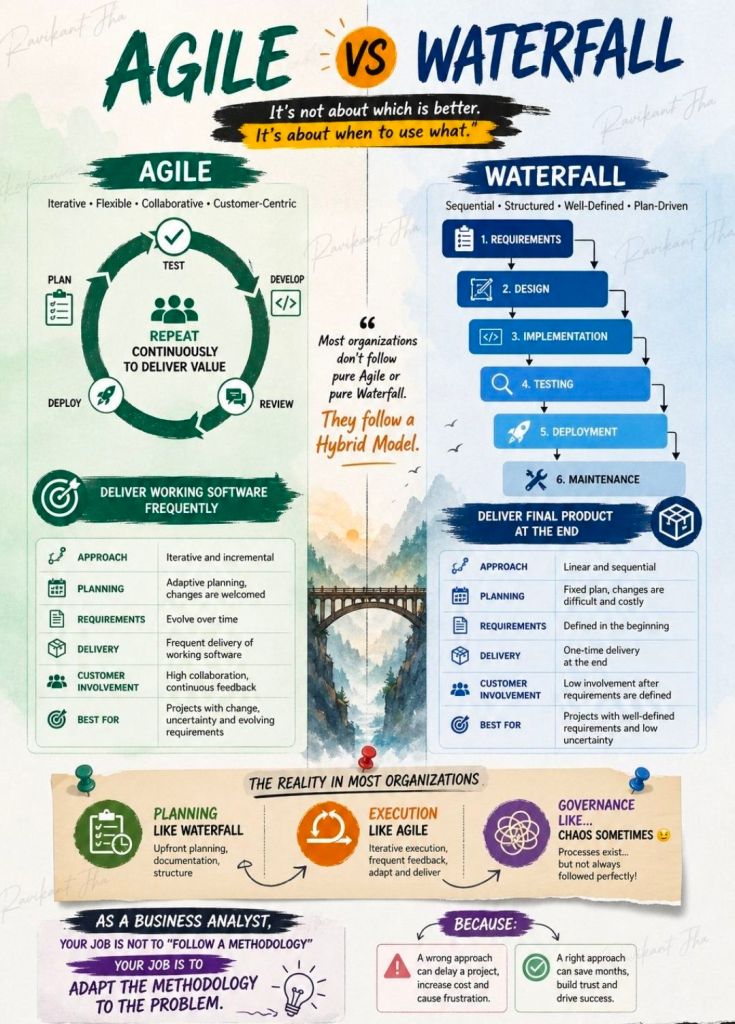
Agile delivery is an iterative approach to project management that focuses on delivering value early, frequently adapting to change, and maintaining continuous customer feedback. Rather than executing a project sequentially, teams break work into small increments to maximize flexibility and product quality.
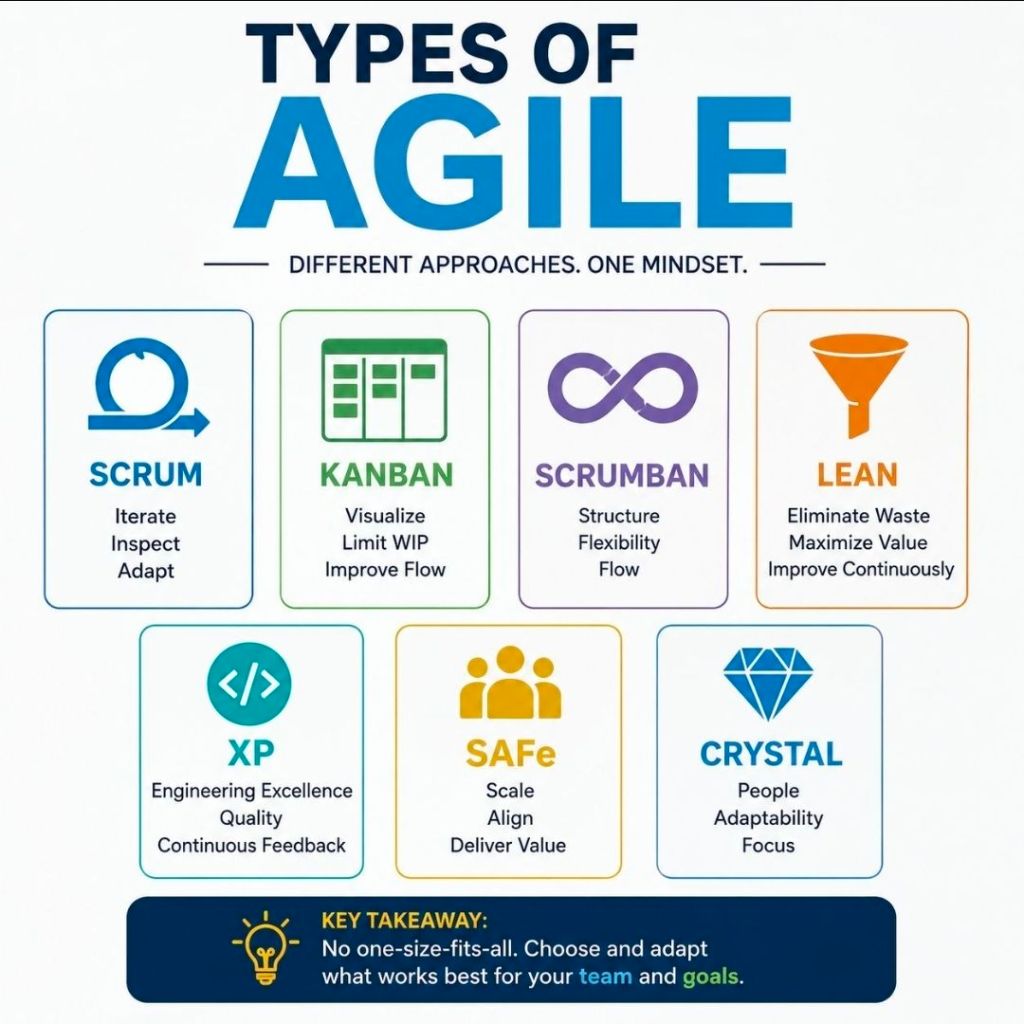
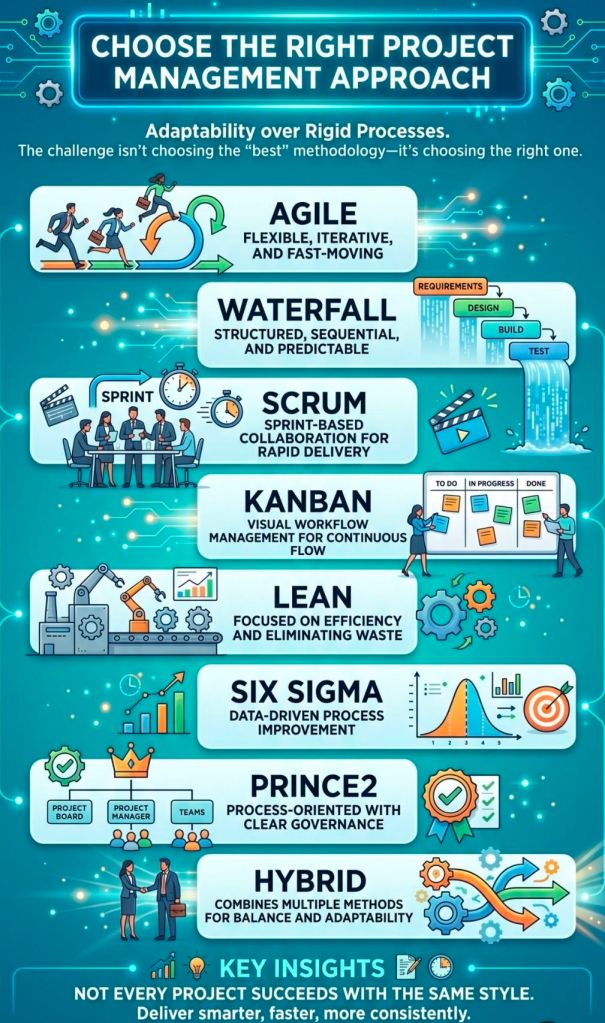
The most common types and frameworks of agile delivery include the following structured methodologies:
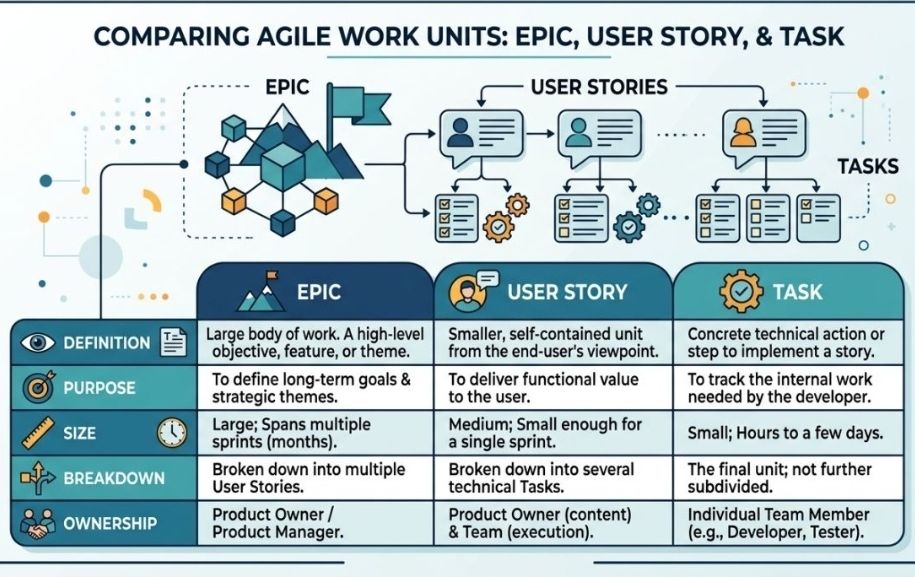
1. Scrum
Scrum is the most widely used agile framework, characterized by highly structured, time-boxed iterations called Sprints (typically 1 to 4 weeks long).
Key Concept: Teams work toward a single, actionable goal during each sprint.
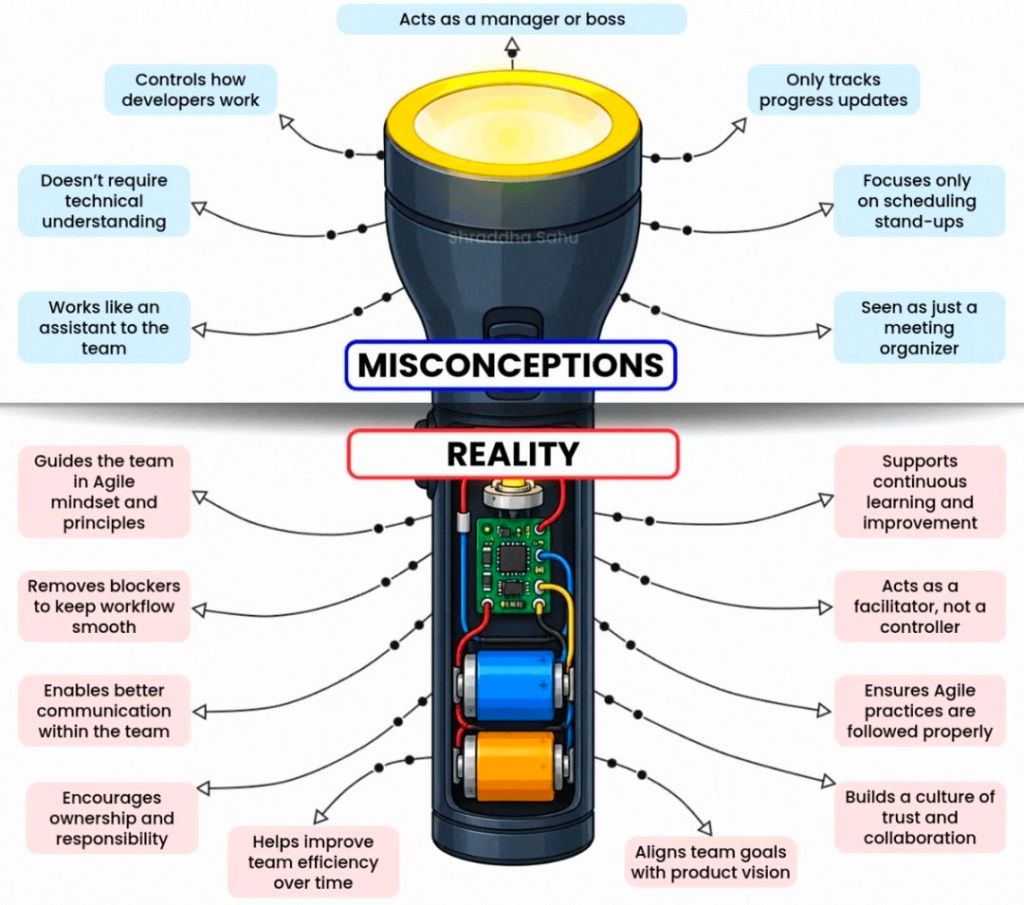
Key Roles: Product Owner (represents the customer), Scrum Master (removes obstacles and enforces the framework), and Developers.
Best For: Projects where requirements change frequently and close collaboration with clients is required.
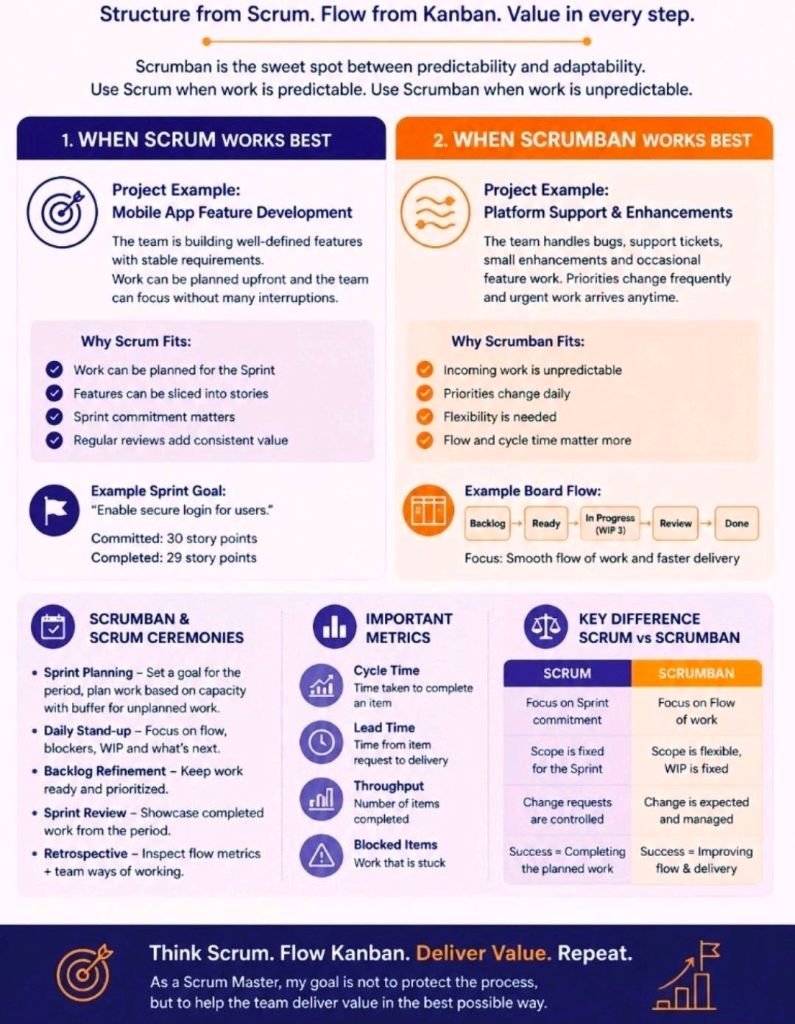
2. Kanban
Kanban is a visual workflow management system that emphasizes continuous delivery and transparency without strict time-boxed iterations.
Key Concept: Work is tracked on a Kanban board divided into columns (e.g., “To Do,” “In Progress,” “Done”).
Key Roles: Self-organizing teams with a pull-based approach.
Best For: Operational workflows, support/maintenance teams, and organizations that need to limit “work in progress” (WIP) to prevent bottlenecks.
3. Lean Software Development
Adapted from Toyota’s lean manufacturing principles, Lean focuses on maximizing customer value while minimizing waste.
Key Concept: Focuses on “eliminating waste” (anything that doesn’t add value to the end user), amplifying learning, and delivering as fast as possible.
Best For: Optimizing overall organizational workflows and reducing overhead.
4. Extreme Programming (XP)
XP focuses heavily on technical excellence and software engineering practices to boost product quality and responsiveness.
Key Concept: Uses practices like pair programming, test-driven development (TDD), and continuous integration.
Best For: Development teams that need to release updates frequently while maintaining strict quality and low bug rates.
5. Feature-Driven Development (FDD)
FDD is a model-driven approach that is highly structured and focuses on building software in short, feature-by-feature iterations.
Key Concept: Work revolves around creating detailed software models and planning by specific features, which are built one by one.
Best For: Teams that prefer structured, step-by-step processes or environments with traditional hierarchical structures.
6. Scaled Agile Framework (SAFe)
SAFe is designed for larger enterprises that need to align cross-functional, multiple Agile teams toward a single business strategy.
Key Concept: Blends Lean, Agile, and DevOps principles to coordinate alignment, governance, and delivery across a massive scale.
Best For: Large organizations and complex projects requiring multiple teams to coordinate efforts.
Preparing for an Agile Scrum interview requires a mix of theoretical knowledge, situational problem-solving, and a clear understanding of your specific role (Scrum Master, Product Owner, or Developer). Be ready to discuss the Scrum framework, roles, artifacts, ceremonies, and how you foster self-organization and continuous improvement.
Review these common Agile Scrum interview questions, categorized by topic:
1. Fundamentals & Frameworks
What is the difference between Agile and Scrum? Agile is an overarching project management philosophy focused on iterative development and flexibility. Scrum is a specific, lightweight framework within Agile that uses set roles, artifacts, and timeboxed “sprints” (usually 1-4 weeks).
What are the core roles on a Scrum Team? The three primary roles are the Product Owner (maximizes value, owns the backlog), the Scrum Master (servant-leader, removes impediments, ensures Scrum rules are followed), and the Developers (cross-functional team that delivers the increment).
What is a “Spike”? A spike is a timeboxed research or exploration task used to reduce uncertainty, figure out a technical approach, or better understand a requirement before development begins.
2. Scrum Ceremonies (Events)
What happens during a Sprint Planning meeting? The team collaborates to determine what work can be delivered in the upcoming sprint and creates a plan (the Sprint Backlog) for how to achieve this Product Goal.
Can you give a 2-3 minute overview of the Daily Scrum? It is a 15-minute timeboxed event for the Developers to inspect progress toward the Sprint Goal and adapt the upcoming work. It is not a status report to management; it is for the team to synchronize and plan the next 24 hours.
What is the purpose of a Sprint Retrospective? Held at the end of every sprint, the team inspects the past sprint regarding people, relationships, processes, and tools. The goal is to identify what went well and create a plan for implementing improvements.
What is the difference between a Sprint Review and a Retrospective? The Review inspects the software/product increment to adapt the Product Backlog. The Retrospective inspects the team’s process and working environment.
3. Artifacts & Estimation
What is the Definition of Done (DoD)? It is a shared, clear checklist of criteria that must be met for a product increment to be considered ready for release. It ensures consistency and quality across the team.
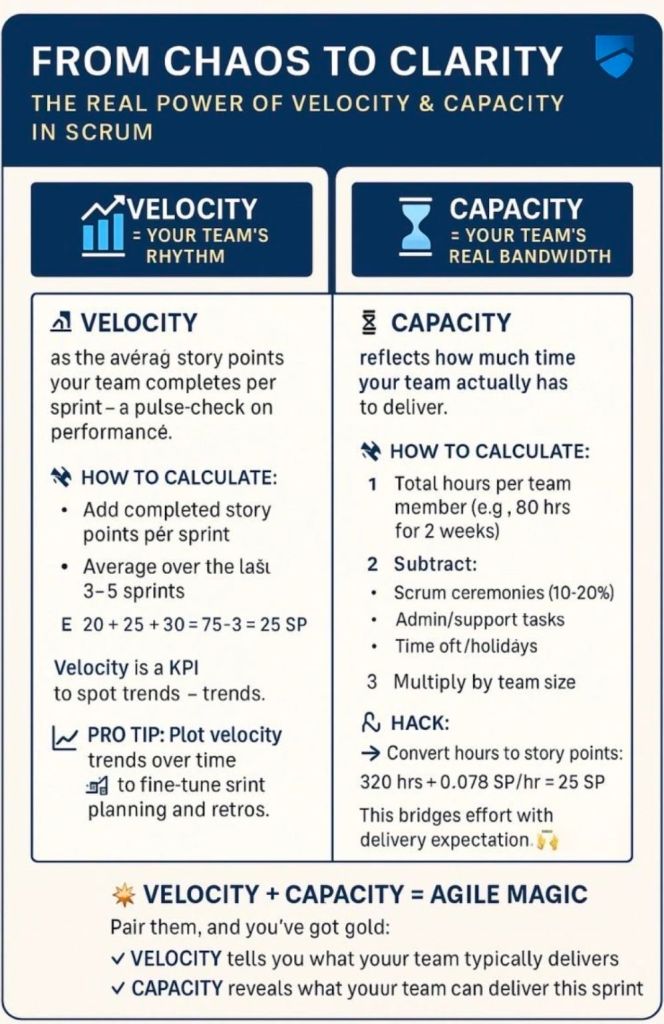
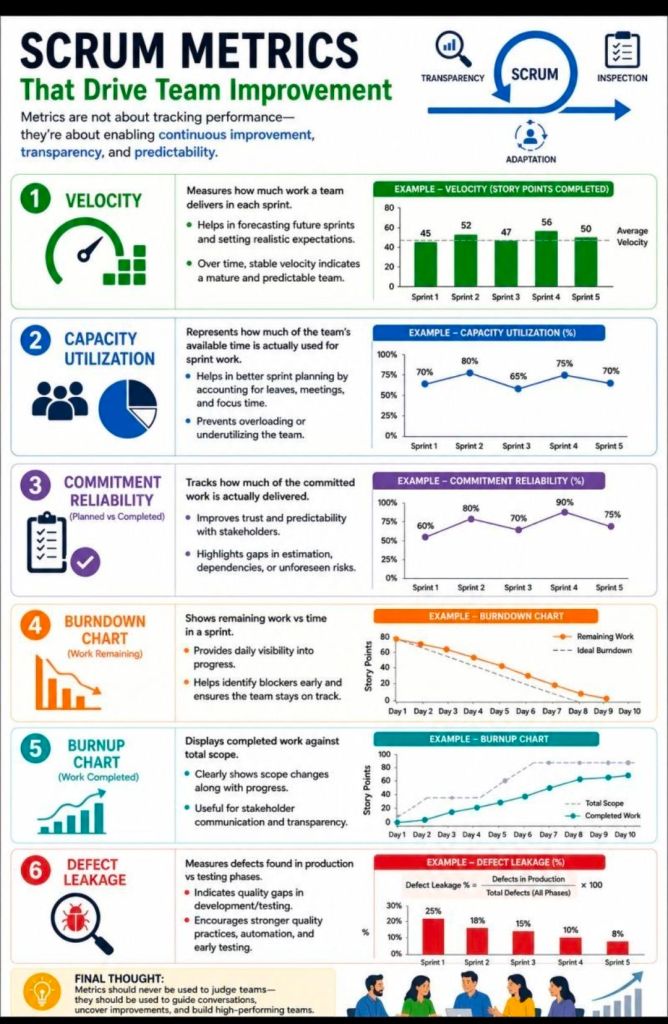
What is Velocity? Velocity measures the total amount of work (usually in Story Points) a Scrum Team can deliver during a single sprint. It is typically calculated as an average over the last 3-4 sprints and helps predict future delivery.
How do you handle scope creep? Emphasize that in Scrum, the sprint scope is locked once the sprint starts. If new work is urgent, it should go to the Product Backlog for future planning, or the team can negotiate with the Product Owner to remove an equally sized task from the current sprint to make room.
What do you do if a manager tries to dictate or assign tasks to the team? Coach the manager on Scrum principles (self-management) and act as a shield to protect the team from outside interference, allowing them to focus on the Sprint Goal.
How do you build trust with your team? Focus on empathy, transparency, consistency, and active listening. Build a safe space where the team can fail forward, experiment, and voice concerns without fear of retaliation.
How do you handle conflict within the team? Encourage the team to resolve conflicts themselves first, stepping in only if it affects the sprint goals. Facilitate open dialogue focusing on the issue (the process/problem), not the person.
Requirements Traceability Matrix RTM & Business Analyst BA
A Requirements Traceability Matrix (RTM) is a structured project management document that links user and stakeholder requirements directly to their corresponding design elements, development deliverables, and verification test cases.
Acting as a living checklist throughout the project life cycle, its primary purpose is to ensure 100% test coverage, validate that all client requests are fulfilled, and prevent scope creep by identifying undocumented work.
The visual layout of a typical RTM template maps individual requirement rows against critical validation milestones.
🔄 Three Main Types of Traceability
The configuration of an RTM depends heavily on the direction of tracking needed for the project:
Forward Traceability: Tracks requirements forward into design, code, and test cases. It ensures the project executes every requested feature and that nothing gets left behind.
Backward (Backward-Looking) Traceability: Traces test cases and final deliverables back to the original requirement. It checks for scope creep, confirming that no extra, unauthorized features were added.
Bidirectional Traceability: Combines both approaches. It links requirements from origin to destination and vice versa, providing clear visibility during change management or troubleshooting.
📋 Structured Breakdown of RTM Content
A standard RTM is formatted as a multidimensional table. Below is the foundational structure, broken down into its logical data components:
1. Core Requirement Parameters
Requirement ID: A distinct alphanumeric identifier (e.g., REQ-001, BRD-102) for quick cross-referencing.
Requirement Type: Classifies the item (e.g., Business, Functional, Technical, UI, Security, or Regulatory Compliance).
Requirement Description: A concise textual explanation defining exactly what the feature or system must achieve.
Source/Origin: The document, stakeholder, client request, or meeting minutes where the requirement originated.
Priority Level: The urgency ranking of the item, usually categorized as High, Medium, or Low (or via MoSCoW ranking).
2. Design and Development Artifacts
Functional Specification ID: Links the requirement to the specific section of the functional design document.
Technical Design/Architecture Module: Points to the code packages, database tables, or system architectural components implementing the requirement.
3. Verification & Validation (Testing) Data
Test Case ID: The unique ID of the specific test cases designed to validate the feature (e.g., TC-101, TC-102).
Test Case Description/Objective: A snapshot of what the test case actually checks.
User Acceptance Testing (UAT) ID: Specific ID linking to end-user validation scenarios.
4. Execution & Quality Control Tracking
Test Execution Status: The real-time health indicator of the testing suite (e.g., Passed, Failed, Blocked, Not Run).
Defect/Bug ID: If a test fails, this column logs the active issue tracker ID (e.g., Jira ticket BUG-404) linked to the breakdown.
Current Deployment Status: Defines the project readiness stage (e.g., In Progress, Dev, QA, Production).
💡 Core Benefits of Maintaining an RTM
Prevents Missed Features: Verifies that every business requirement translates into clean code and valid testing cycles before software deployment.
Streamlines Change Management: If a client alters a feature, developers can quickly scan the RTM row to see exactly which code modules and test scripts need updates.
Simplifies Compliance Audits: Serves as regulatory proof in safety-critical landscapes (like medical devices or automotive software) that every target function passed validation.
Requirements Traceability Matrix RTM & Business Analyst BA
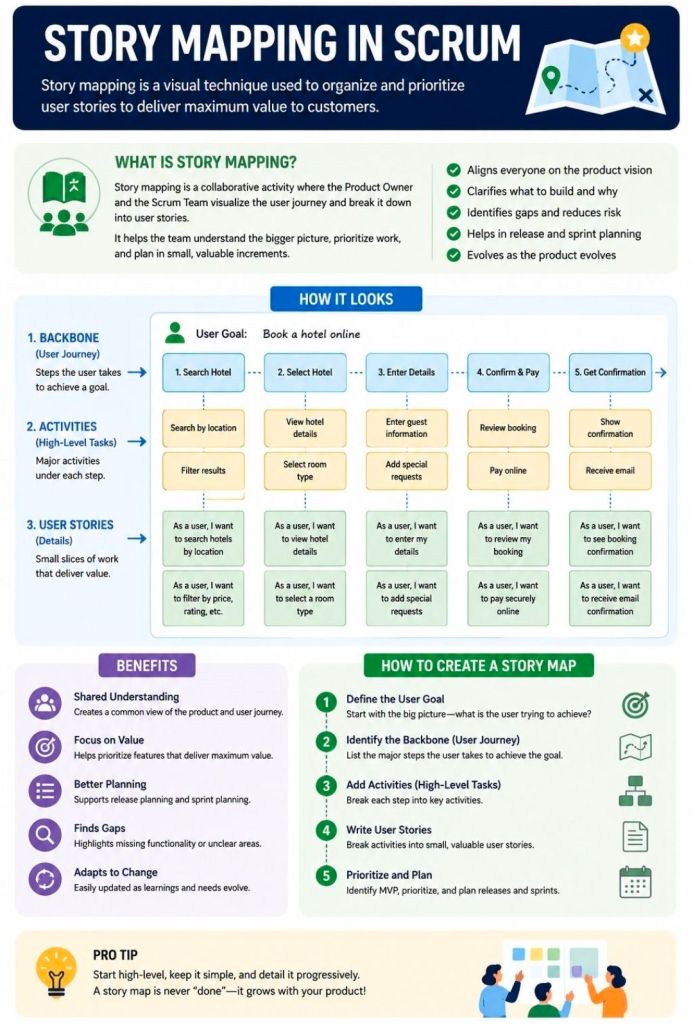
Story Mapping in Agile and Scrum is a visual technique that organizes user stories along a chronological user journey. It helps teams see the big picture, avoid flat, disconnected backlogs, and collaborate on planning iterative releases that consistently deliver user value.
How a Story Map is Structured
A story map is a two-dimensional grid—often built with sticky notes on a whiteboard or via software like Miro or Visual Paradigm. It breaks work down into three levels of hierarchy:
Horizontal Axis (The Spine): Arranges the customer journey chronologically.
Activities: The broadest goals a user wants to achieve (e.g., “Checkout”).
Steps: The specific tasks required to complete the activity (e.g., “Enter Shipping Info,” “Pay”).
Vertical Axis (Details & Priority): Stacks beneath each step are the detailed user stories, epics, or features. They are organized by priority, with the most critical or highly sophisticated tasks at the top.
The Benefits of Story Mapping
Teams use this technique—popularized by Jeff Patton—to achieve several core Agile goals:
Prevents “Flat Backlog” Blindness: Gives stakeholders and developers a birds-eye view of how the entire application or feature fits together.
Defines the MVP: Allows teams to draw horizontal “release lines” across the map. The items sitting above this line form the barebones “walking skeleton” or Minimum Viable Product (MVP).
Aids Sprint Planning: Helps the Product Owner pull well-sequenced, context-aware stories directly into sprint backlogs.
Fosters Collaboration: Moves the team away from siloed requirement docs and toward collaborative conversations around actual user behavior.
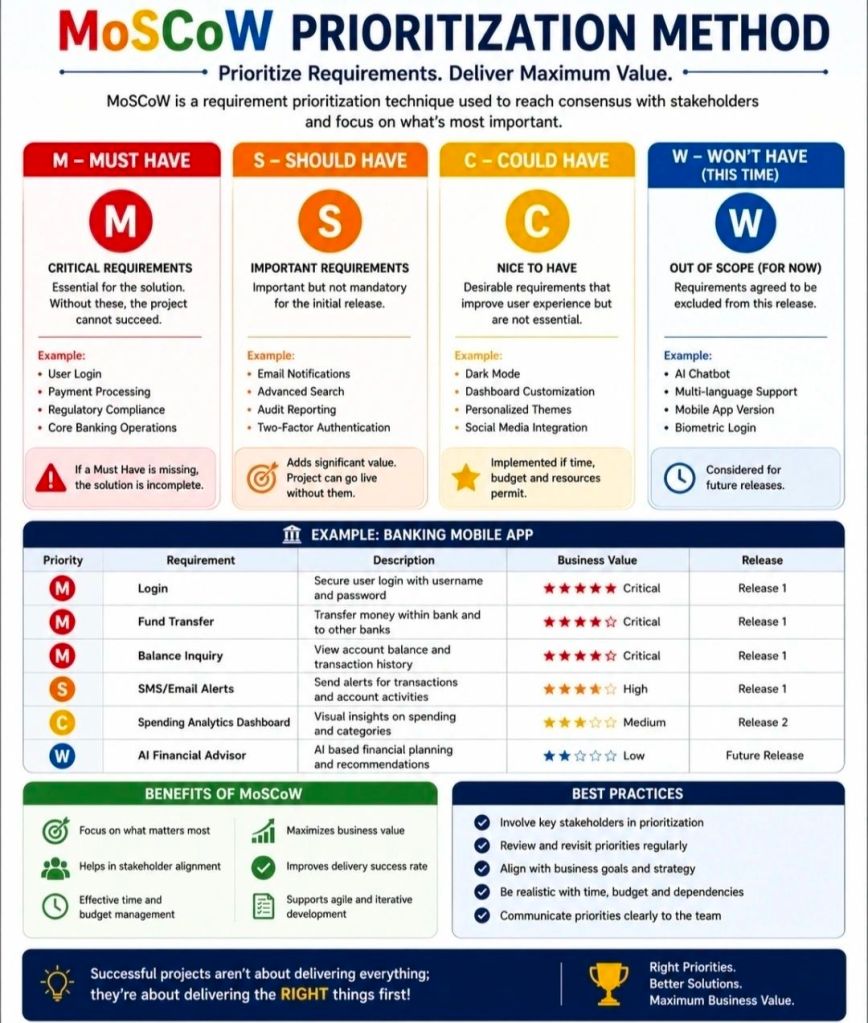
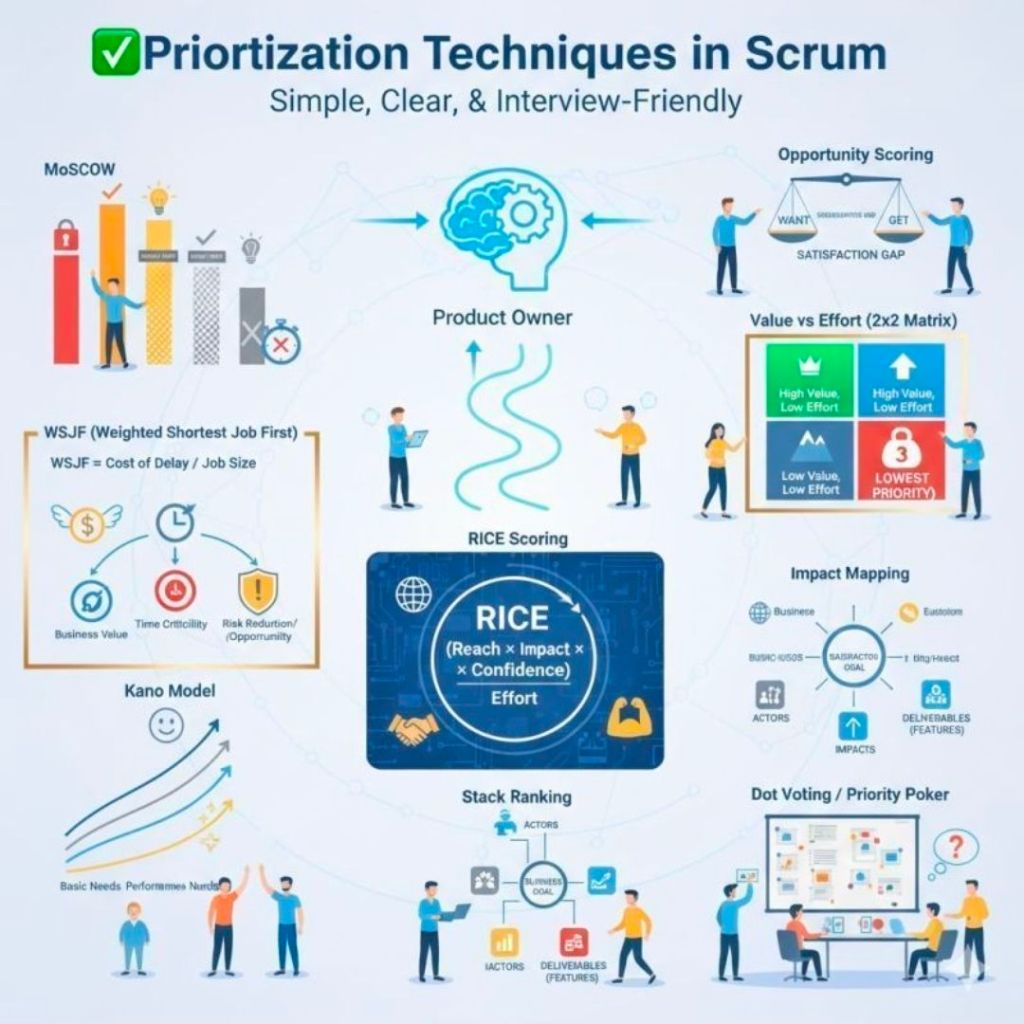
The MoSCoW method is a popular requirements prioritization technique used in project management and software development to help stakeholders reach a common understanding on the importance of deliverables. It categorizes tasks into Must, Should, Could, and Won’t have.
The MoSCoW Categories
Must Have: Non-negotiable requirements that are critical for success, compliance, or safety. Without these, the project is considered a failure and cannot be deployed.
Should Have: High-priority, important features that add significant value but are not strictly vital for immediate delivery. These are generally included if time permits, or they may have a manual workaround.
Could Have: Desirable, “nice-to-have” features that are small and easy to implement. These improve user experience but can be deferred or dropped without impacting the project’s overall success.
Won’t Have (or Won’t Have this time): Features that have been mutually agreed upon as out-of-scope for the current release or timeframe. They are deliberately excluded to prevent scope creep, though they may be added to the backlog for future cycles.
Why and When to Use It
Resource Management: It helps maximize limited time, budget, and resources by focusing effort on the features that provide the most immediate ROI.
Stakeholder Alignment: It acts as a negotiation tool, forcing stakeholders to agree on what is genuinely critical versus what is purely desirable.
Agile Environments: It is a foundational practice in Agile frameworks like DSDM, where teams adhere to fixed deadlines (timeboxes) and adjust the project scope instead.
Best Practices for Implementation
The 60-20-20 Rule: A common best practice is to ensure that Must Haves consume no more than 60% of the team’s total effort. Roughly 20% should be allocated to Should Haves, and 20% reserved for Could Haves to act as contingency room.
Challenge Assumptions: When classifying a requirement as a Must, ask: “What happens if we don’t do this? Can we still deploy the product?” If the project can still function—even awkwardly—it is likely a Should or Could.
Continuous Review: Priorities aren’t static. Re-evaluate your MoSCoW list at the end of every sprint or development cycle, as a Could Have from a previous phase might be upgraded or permanently discarded.
Artificial intelligence is transforming project management by shifting software from passive data repositories into active, predictive engines that automate tedious administration and improve decision accuracy.
The breakdown below covers the primary AI approaches and the specific tools driving each function.
🧠 Core AI Approaches in Project Management
Rather than basic, rule-based automation (“if X happens, do Y”), true AI uses model-driven machine learning, natural language processing (NLP), and predictive analytics.
Predictive Analytics & Forecasting: Machine learning models evaluate past team velocity, budget trends, and historical timelines to forecast delays and cost overruns before they occur.
Natural Language Processing (NLP): Large Language Models (LLMs) digest unstructured data like unstructured chats, customer emails, and meeting transcripts to extract action items, drafting project updates automatically.
Resource Optimisation: Algorithms match team members’ skills, existing workloads, and availability with upcoming project requirements to distribute work sustainably and efficiently.
Proactive Risk & Scope Creep Detection: AI monitors real-time activity and flags deviations from the initial project charter, alerting teams to emerging bottlenecks.
🛠️ AI Project Management Tools Broken Down by Use Case
1. All-in-One Work Operating Systems (Work OS)
These comprehensive platforms integrate AI deeply into everyday task tracking, workflows, and communication.
Monday.com: Features an integrated AI Assistant that auto-generates task descriptions, brainstorms project ideas, and summarizes long activity threads across cross-functional workspaces.
ClickUp: Uses its unified “ClickUp Brain” engine to break down major project milestones into contextual subtasks, answer project-related queries instantly, and write status updates.
Asana: Leverages AI smart agents to recommend task assignments, identify workflow blockers early, and suggest ideal task prioritisation based on team capacity.
Wrike: Focuses heavily on predictive analytics and intelligent insights, allowing larger organisations to move past traditional tracking into data-driven risk monitoring.
2. Meeting & Communication Intelligence
These tools alleviate the administrative burden of manually taking notes, tracking ownership, and summarizing align-meetings.
Otter.ai: Transcribes team calls in real time and automatically creates bullet-point action items, keyword summaries, and structured meeting recaps.
Microsoft Copilot / Google Gemini: Seamlessly pulls historical data from your workspace ecosystem (emails, documents, calendars) to draft project charters or assemble stakeholder reports with minimal context.
🛠️ AI Project Management Tools Broken Down by Use Case
1. All-in-One Work Operating Systems (Work OS)
These comprehensive platforms integrate AI deeply into everyday task tracking, workflows, and communication.
Monday.com: Features an integrated AI Assistant that auto-generates task descriptions, brainstorms project ideas, and summarizes long activity threads across cross-functional workspaces.
ClickUp: Uses its unified “ClickUp Brain” engine to break down major project milestones into contextual subtasks, answer project-related queries instantly, and write status updates.
Asana: Leverages AI smart agents to recommend task assignments, identify workflow blockers early, and suggest ideal task prioritisation based on team capacity.
Wrike: Focuses heavily on predictive analytics and intelligent insights, allowing larger organisations to move past traditional tracking into data-driven risk monitoring.
2. Meeting & Communication Intelligence
These tools alleviate the administrative burden of manually taking notes, tracking ownership, and summarizing align-meetings.
Otter.ai: Transcribes team calls in real time and automatically creates bullet-point action items, keyword summaries, and structured meeting recaps.
Microsoft Copilot / Google Gemini: Seamlessly pulls historical data from your workspace ecosystem (emails, documents, calendars) to draft project charters or assemble stakeholder reports with minimal context.
3. Engineering & Agile Backlog Management
Built to address the rapid velocity changes and technical needs of software development teams.
Jira (Atlassian Rovo): Uses built-in AI agents to organize bloated backlogs, surface conflicting dependencies, and estimate how long features will take based on historical sprint velocities.
4. Document & Knowledge Management
Designed for centralizing organizational resources so teams don’t waste time hunting for internal data.
Notion AI: Acts as a central, conversational wiki workspace that synthesizes notes, translates documents, drafts release notes, and surfaces data buried in complex project databases.
NotebookLM: A powerful, localized research assistant that organizes complex internal project documentation, creates study guides for teams, and answers cross-document queries accurately.
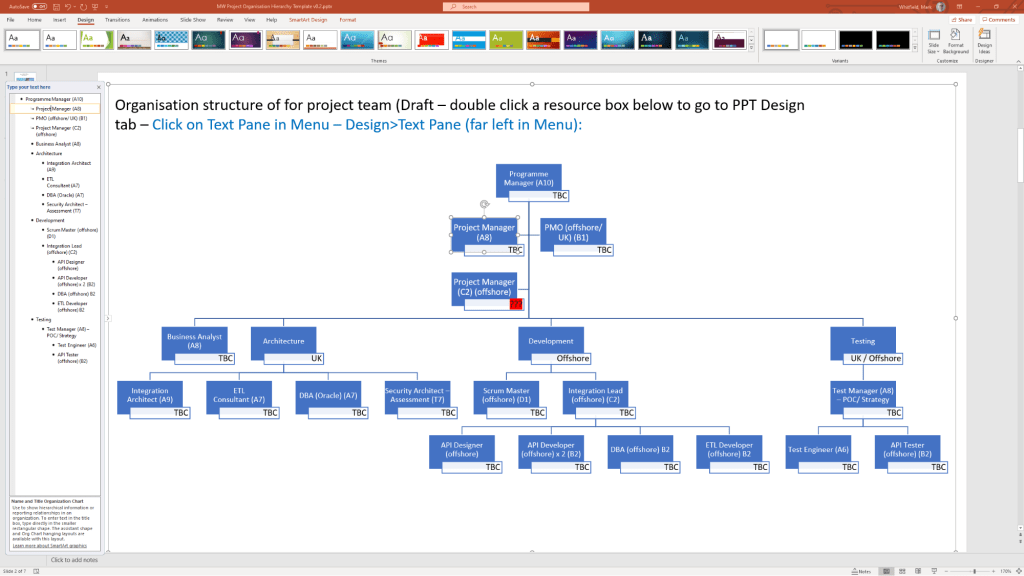
The Project Management Templates by Mark Whitfield constitute a comprehensive toolkit of over 200 editable resources designed to accelerate project delivery across Agile, Waterfall, and PRINCE2 frameworks.
The structural breakdown of the core templates is organised by functional category, specific template, integrated Microsoft Office tool, and operational description:
1. Project Planning & Scheduling
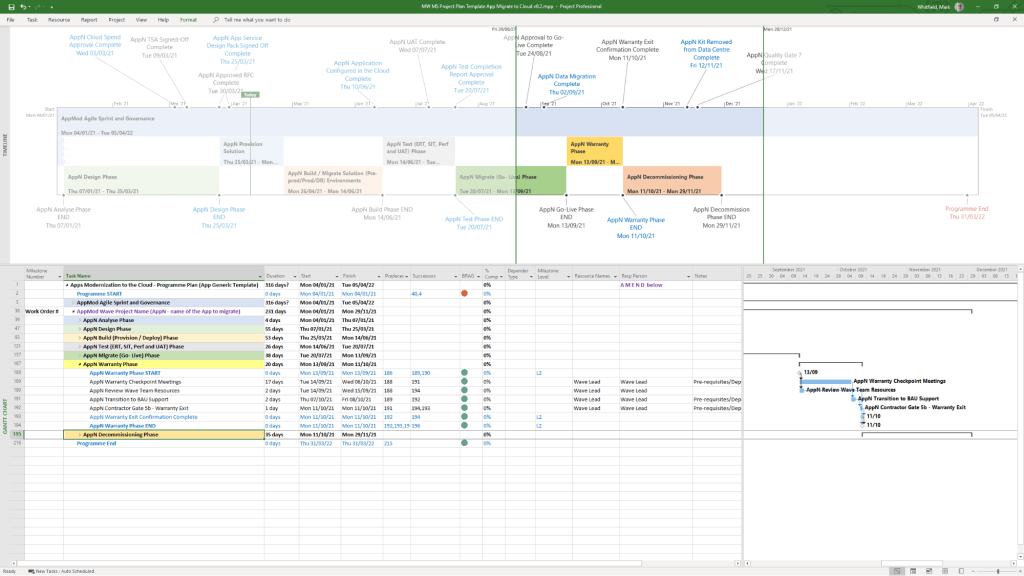
Detailed SDLC Project Plan
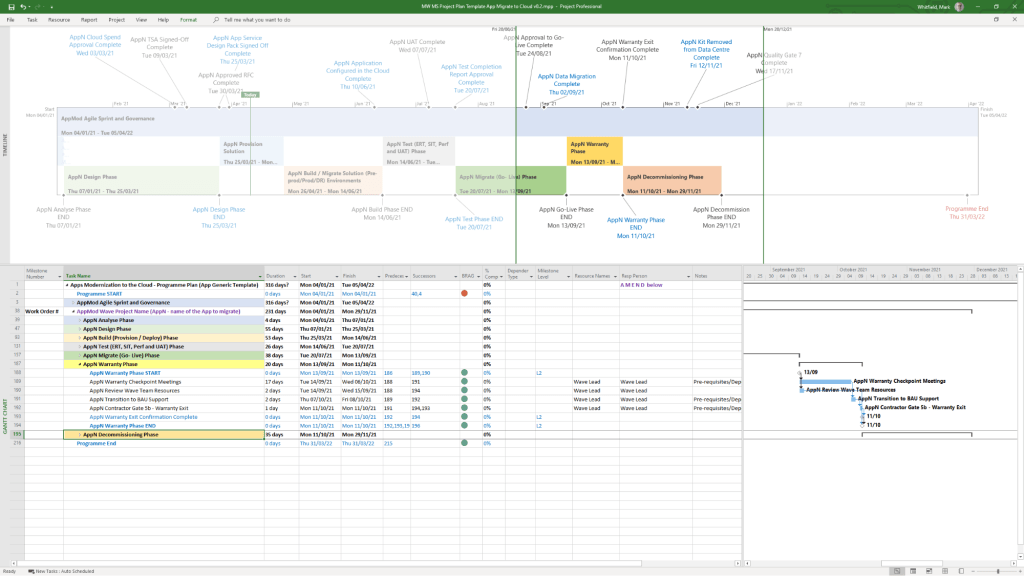
MS Tool: Microsoft Project (.mpp)
Description: A master schedule structured around the Software Development Lifecycle (SDLC) from development through testing, deployment, and Early Live Support (ELS), easily toggled between Agile Scrum and traditional Waterfall.
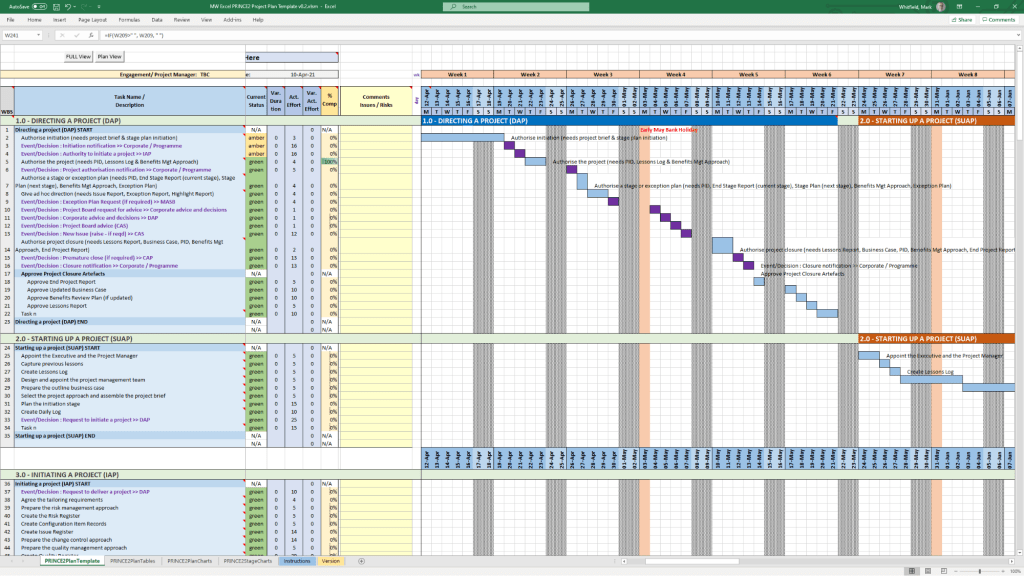
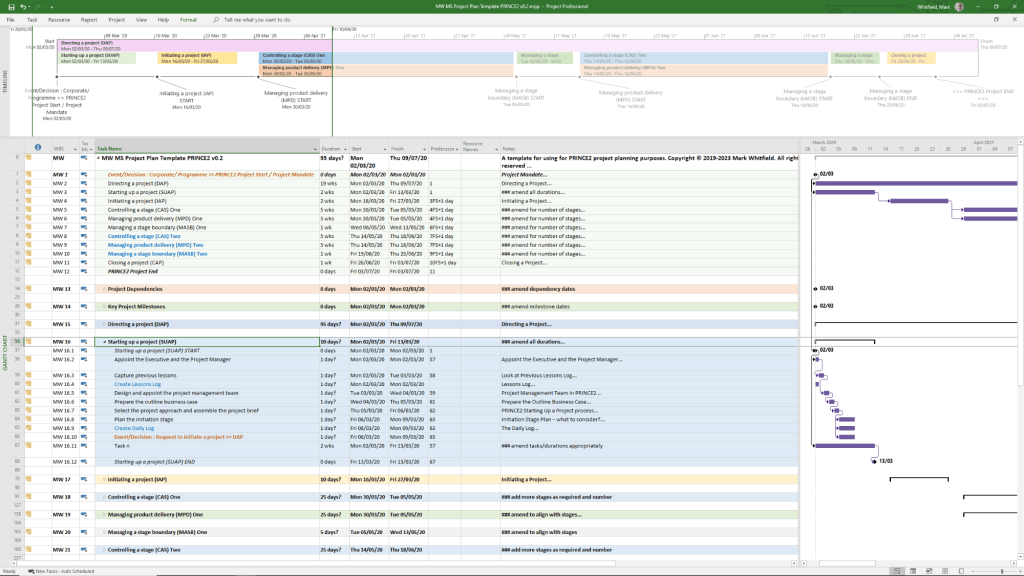
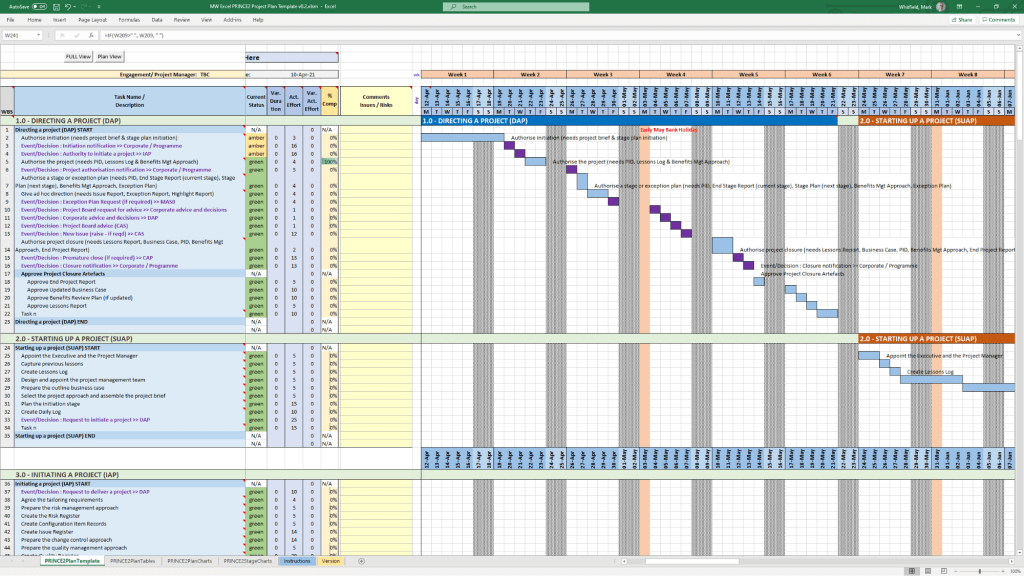
PRINCE2 7th Edition Project Plan
MS Tool: Microsoft Project (.mpp) & MS Excel (.xlsm)
Description: Fully annotated task list aligned with the 7th edition principles, colour-coded by activity type (blue for artifact creation, brown for management decisions, purple for updates).
Detailed Waterfall Project Planner
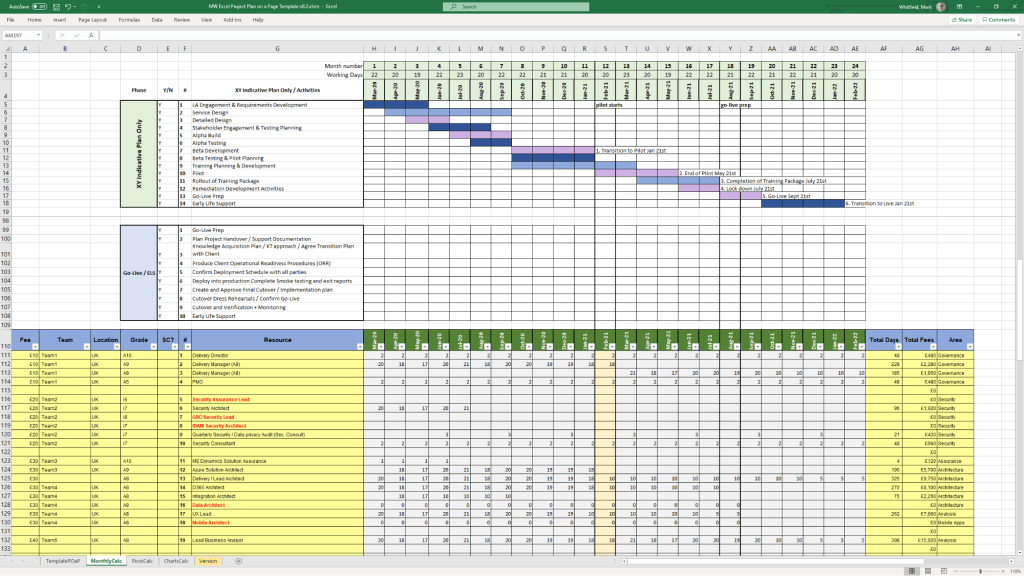
MS Tool: MS Excel
Description: A portable, license-free alternative to MS Project featuring baseline versus forecast tracking, an integrated Gantt chart view, and automated progress charts.
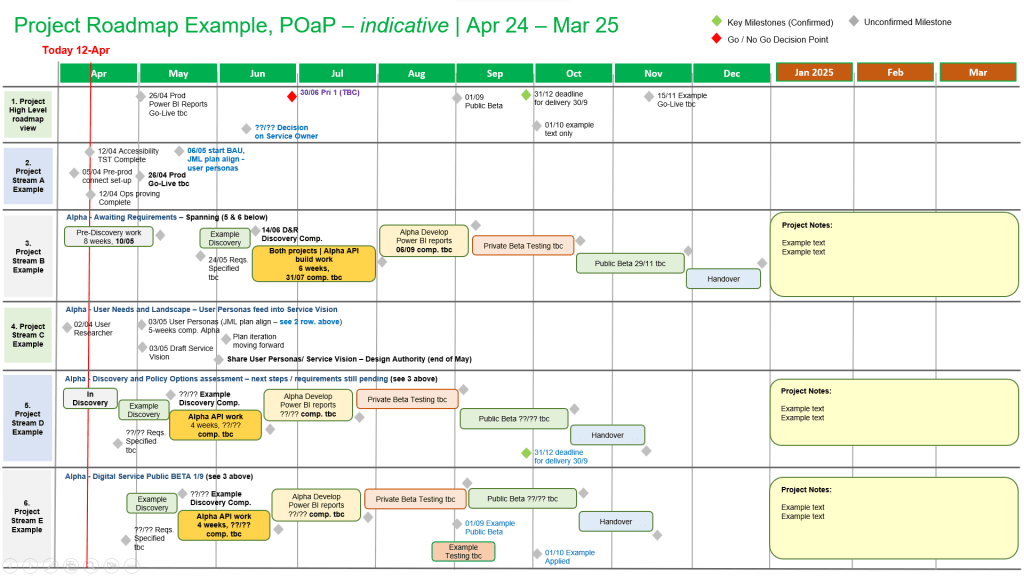
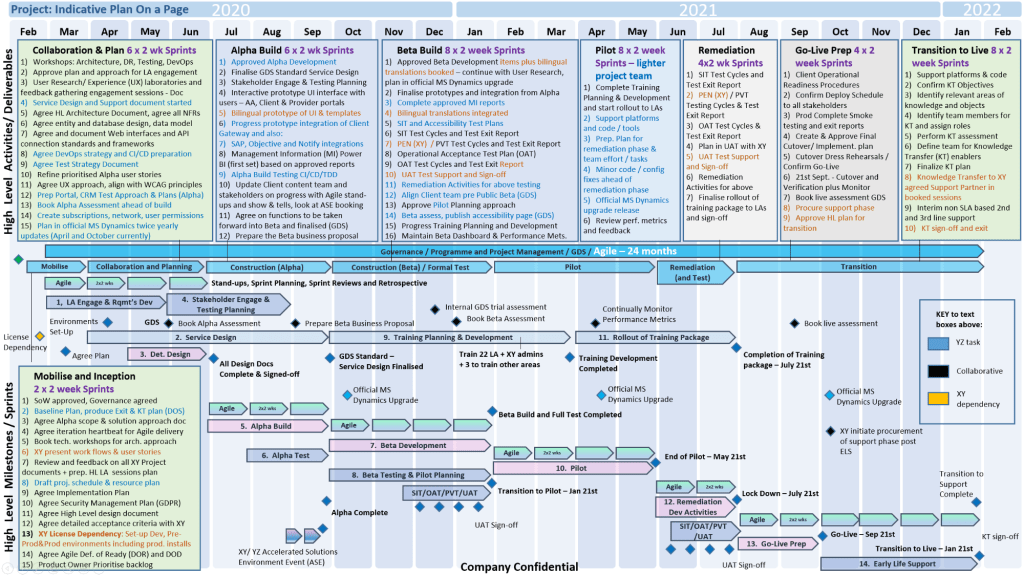
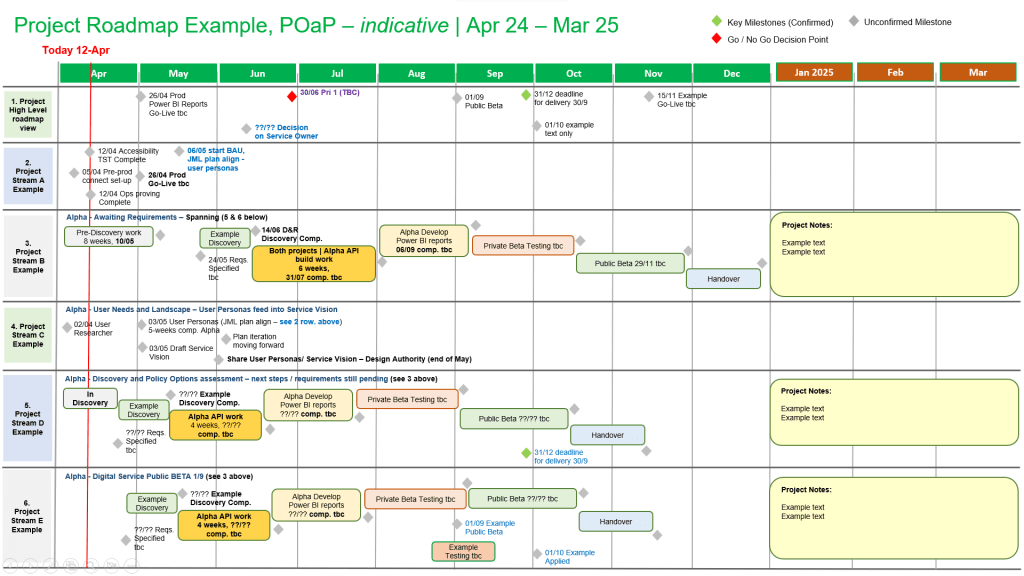
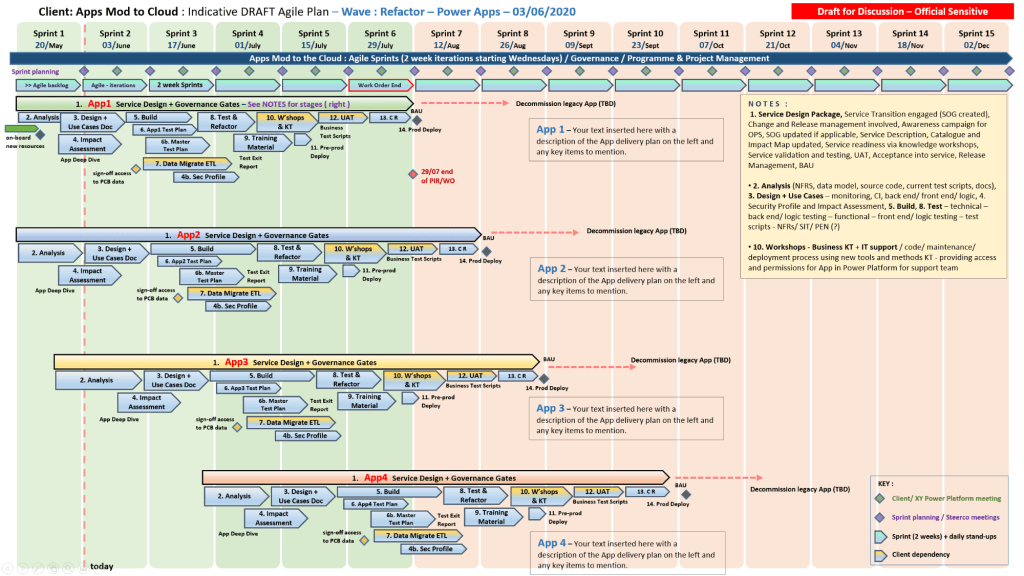
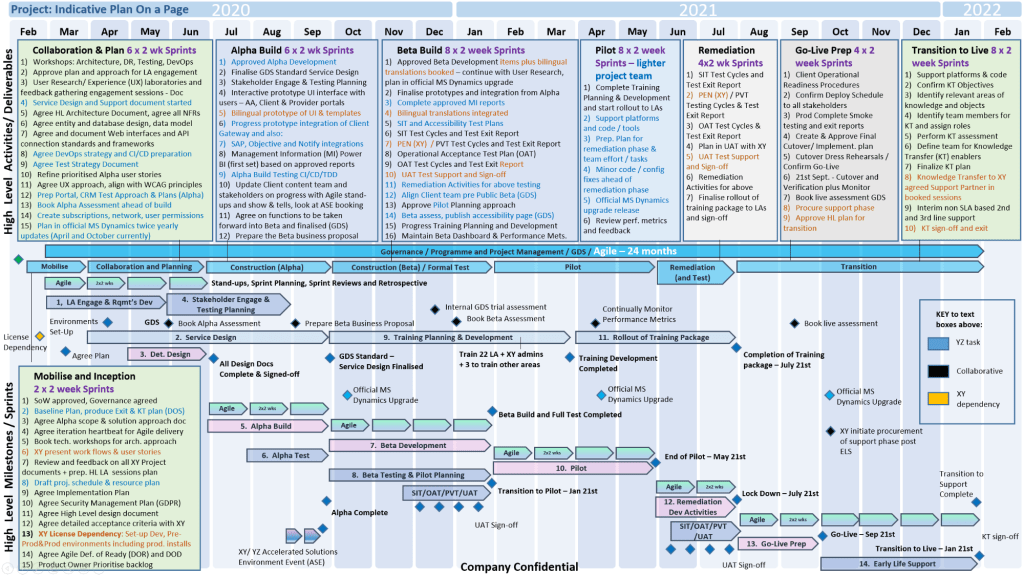
Plan on a Page (POaP)
MS Tool: MS PowerPoint & MS Excel
Description: High-level, executive-ready roadmaps containing over 30 slide variations used to communicate project timelines, key milestones, and work streams to senior stakeholders.
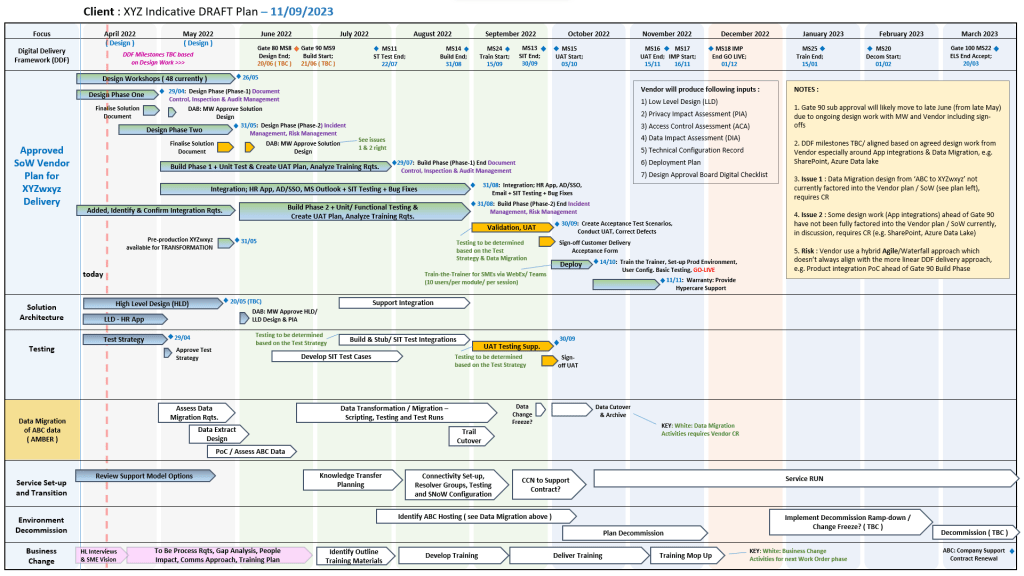
1. Project Planning & Scheduling POAP MS PowerPoint Templates2. Project Planning & Scheduling MS Project Templates3. Project Planning & Scheduling MS Excel Templates
2. Operational Control & Governance
Comprehensive RAID Log & Charts
MS Tool: MS Excel
Description: A highly detailed central registry featuring distinct tabs to track Risks, Actions, Issues, Opportunities, Dependencies, Lessons Learned, and Change Requests alongside visual metric dashboards.
Basic RAIDs Tracker
MS Tool: MS Excel
Description: A scaled-down, simplified version of the master RAID log optimized for quick turnarounds, minor bids, and low-complexity projects.
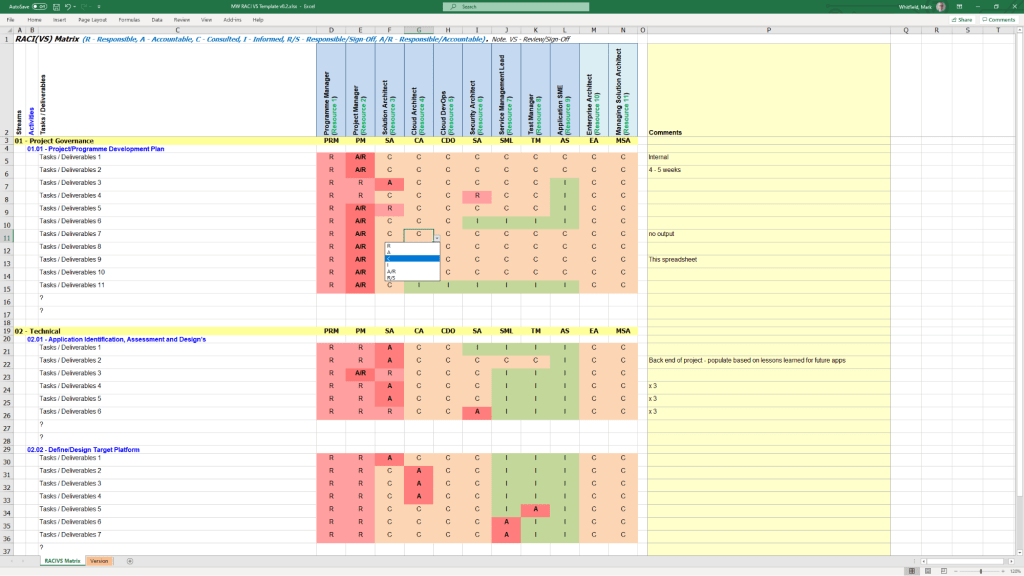
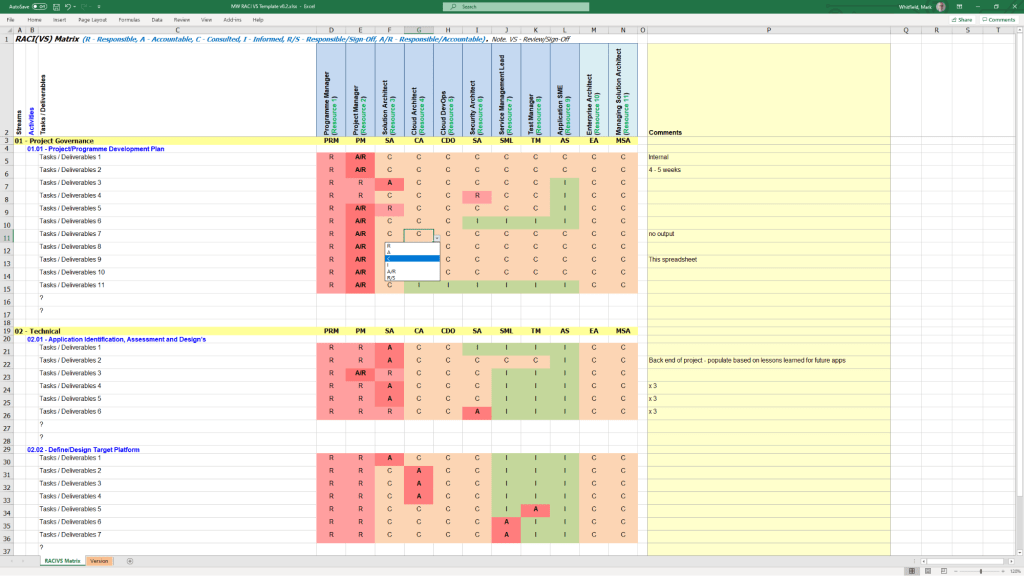
RACI Matrix
MS Tool: MS Excel
Description: A governance sheet mapping project deliverables against specific team roles to clarify who is Responsible, Accountable, Consulted, and Informed.
Agile Story Dependency Tracker
MS Tool: MS Excel
Description: A specialised log to document and track blocker stories tied to external suppliers or client-side dependencies that risk driving scope changes.
1. Operational Control & Governance MS Excel RACI Template
3. Financial & Resource Management
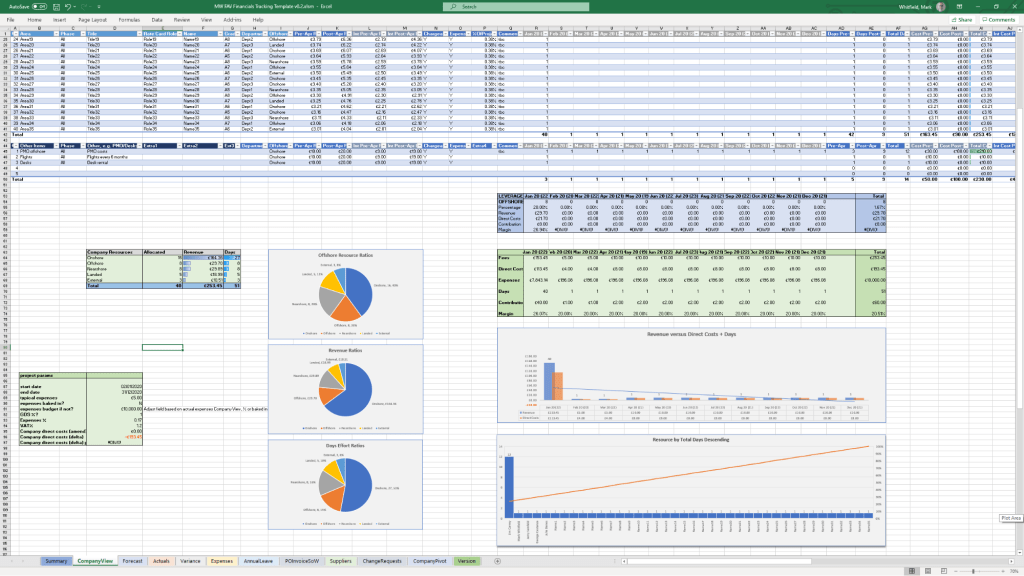
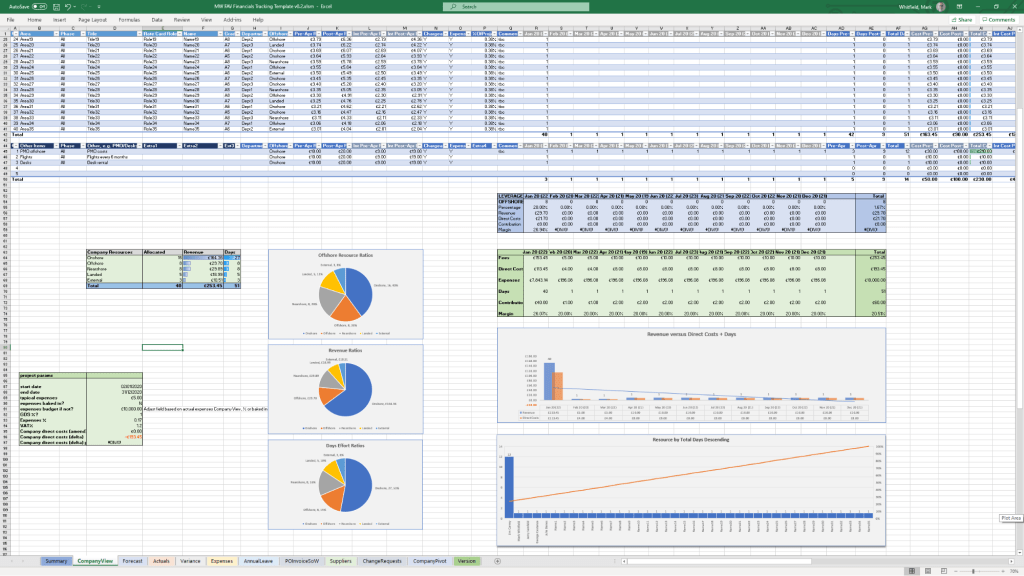
Project Financial Tracker
MS Tool: MS Excel
Description: A financial controller mapping internal and external forecast costs against actuals, factoring in margins, variances, supplier fees, and expense categories.
Resource, Sickness, & Leave Tracker
MS Tool: MS Excel
Description: An operational matrix monitoring annual leave, sickness, and training schedules to adjust resource availability and capacity within the master schedule.
1. Financial & Resource Management MS Excel Templates
4. Agile Delivery Metrics
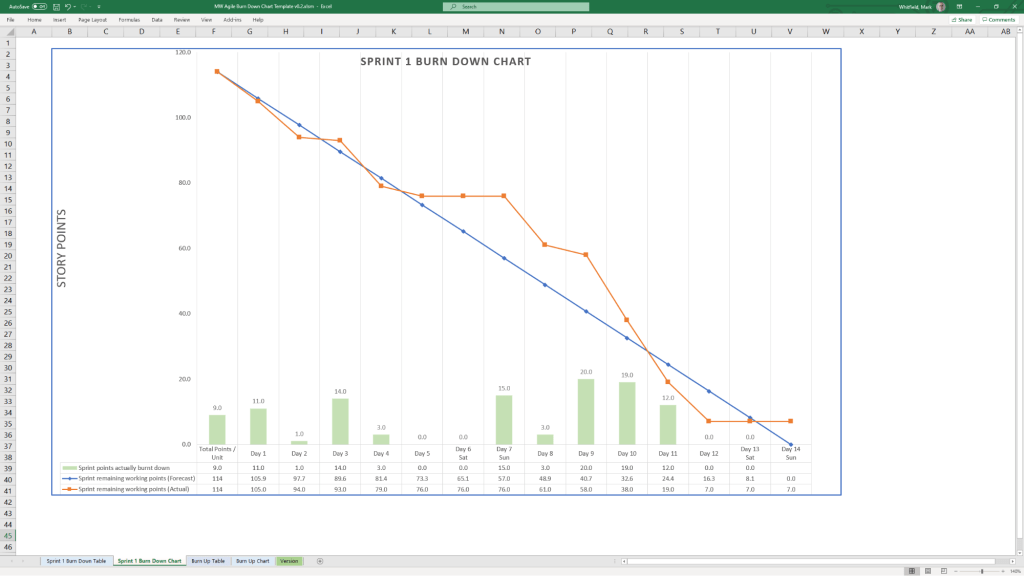
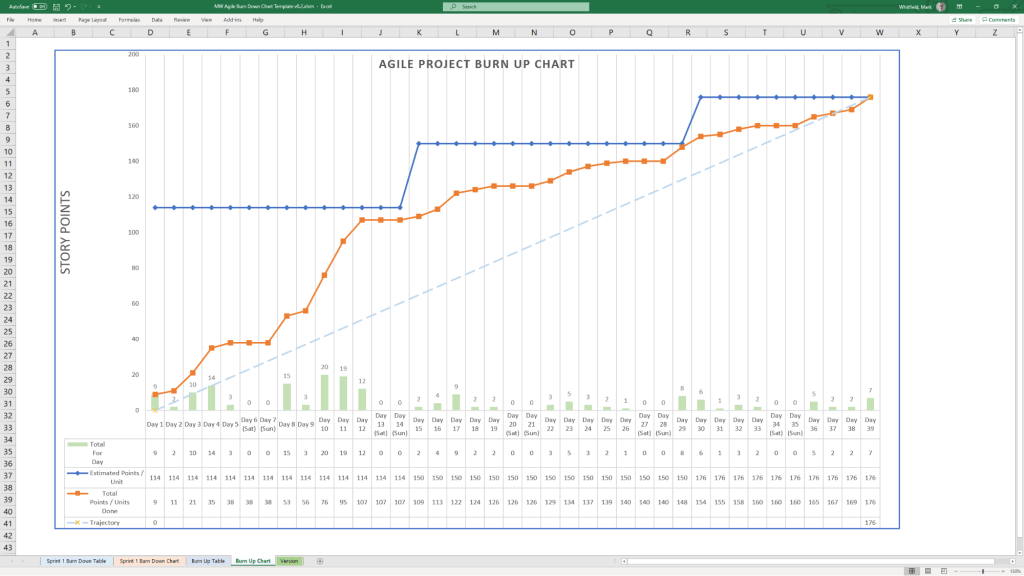
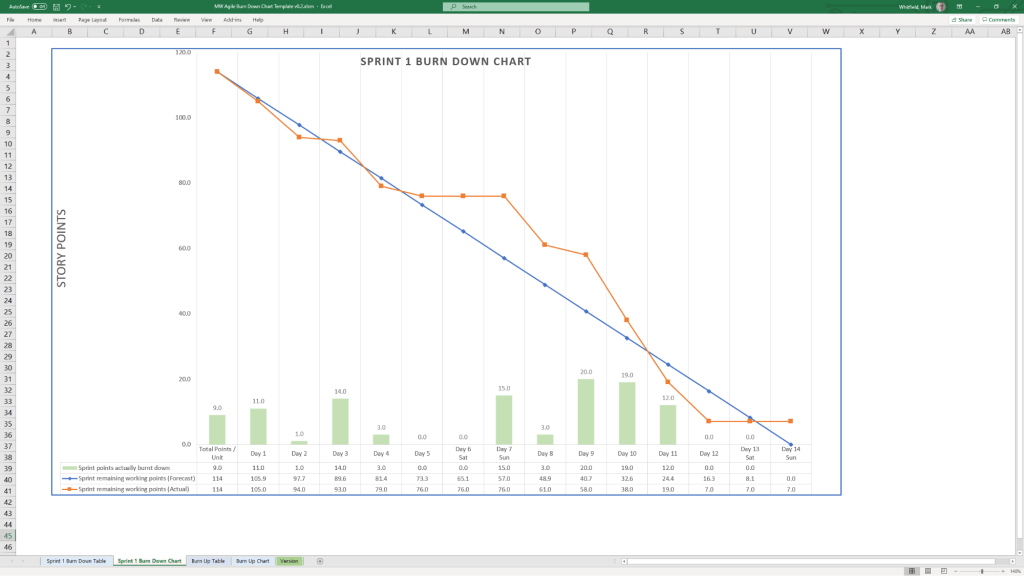
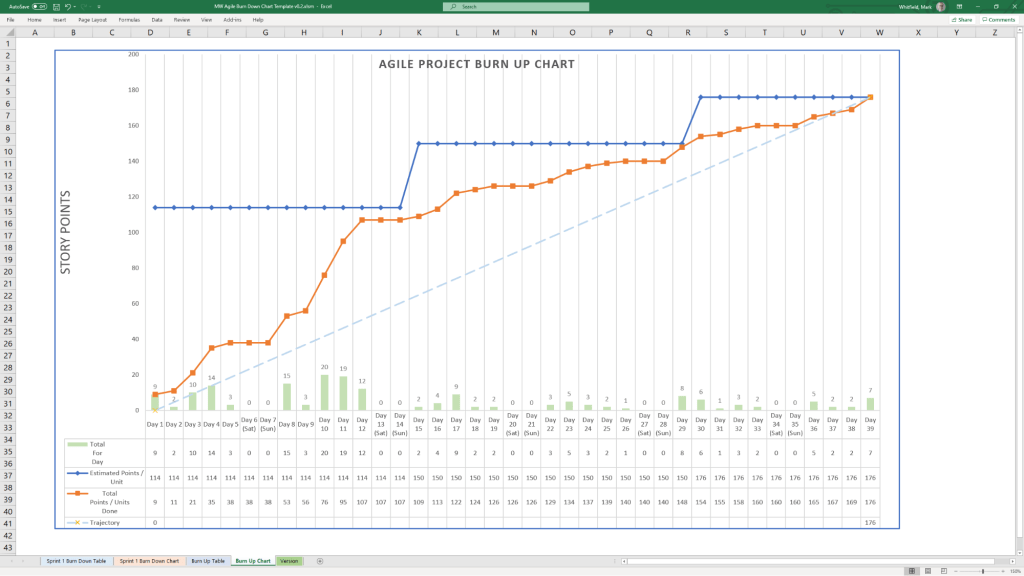
Agile Burn Down & Burn Up Charts
MS Tool: MS Excel
Description: Manual data-table tracking solutions designed to visualise sprint or release velocity for teams operating without access to enterprise tools like Jira.
1. Agile Burn Down Chart in MS Excel Template Example2. Agile Burn Up Chart in MS Excel Template Example
5. Communications & Administration
PRINCE2 Management Products
MS Tool: MS Word (.doc)
Description: A full portfolio of standard documentation masters including Project Initiation Documents (PID), Project Briefs, Highlight Reports, and Business Cases.
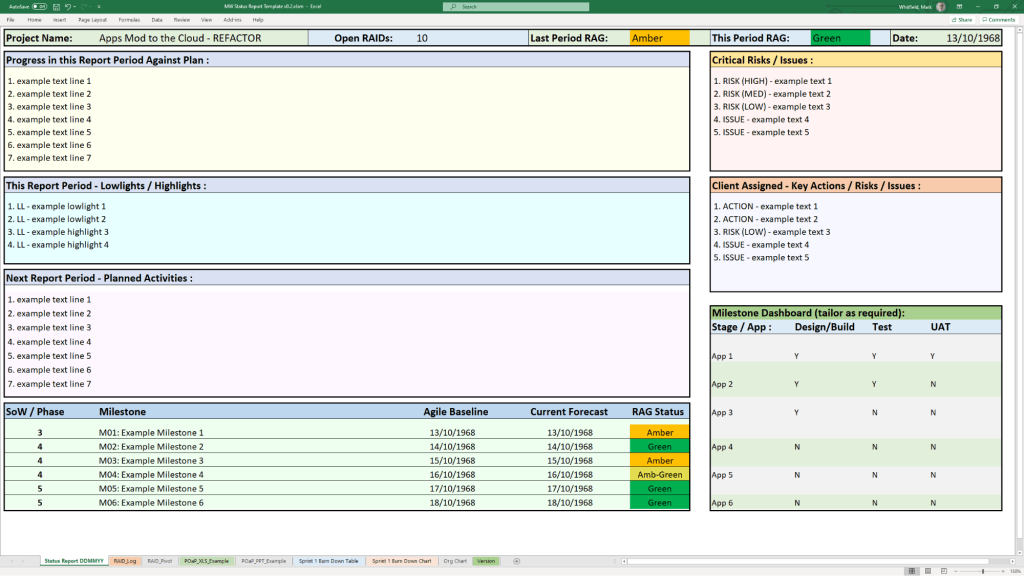
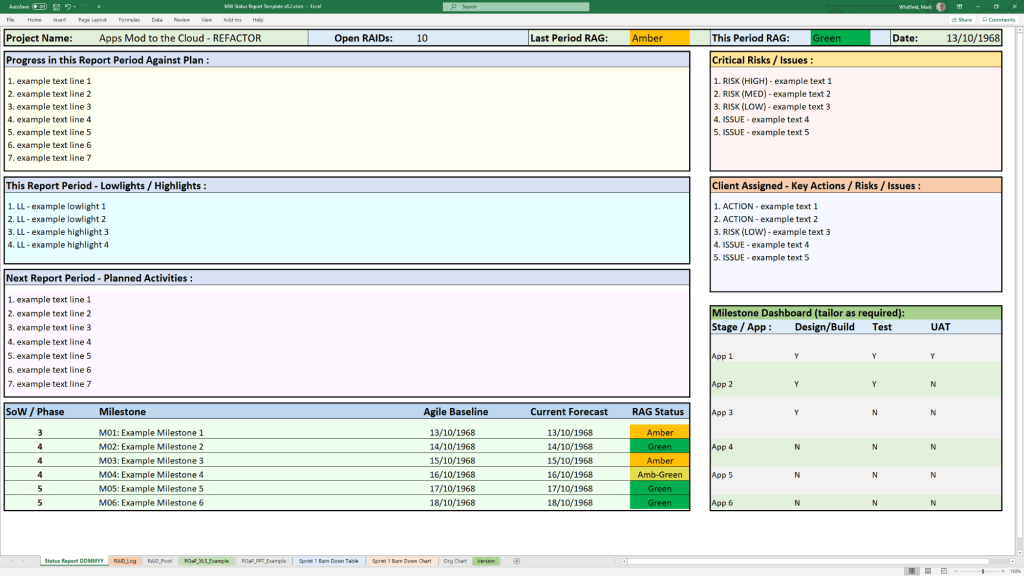
Project Status Report
MS Tool: MS Word & MS PowerPoint
Description: Weekly and monthly progress reporting templates featuring structured sections for milestones, blockers, financial status, and RAG indicators.
Kick-Off Deck & Mobilisation Kit
MS Tool: MS PowerPoint
Description: Onboarding and alignment slide decks designed to define scope, establish ground rules, and guide teams through project initiation.
Meeting Minutes Template
MS Tool: MS Word
Description: An action-oriented meeting layout tailored for capturing critical decisions, owners, and deadlines uniformly.
1. Communications & Administration MS Excel Status Report Template Example
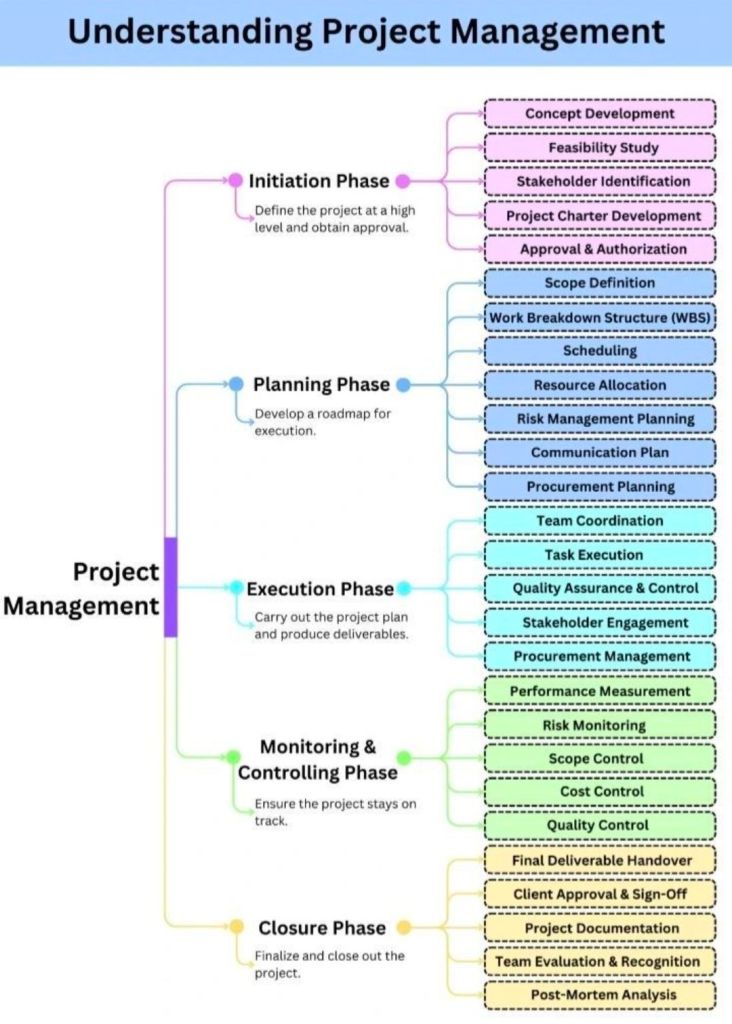
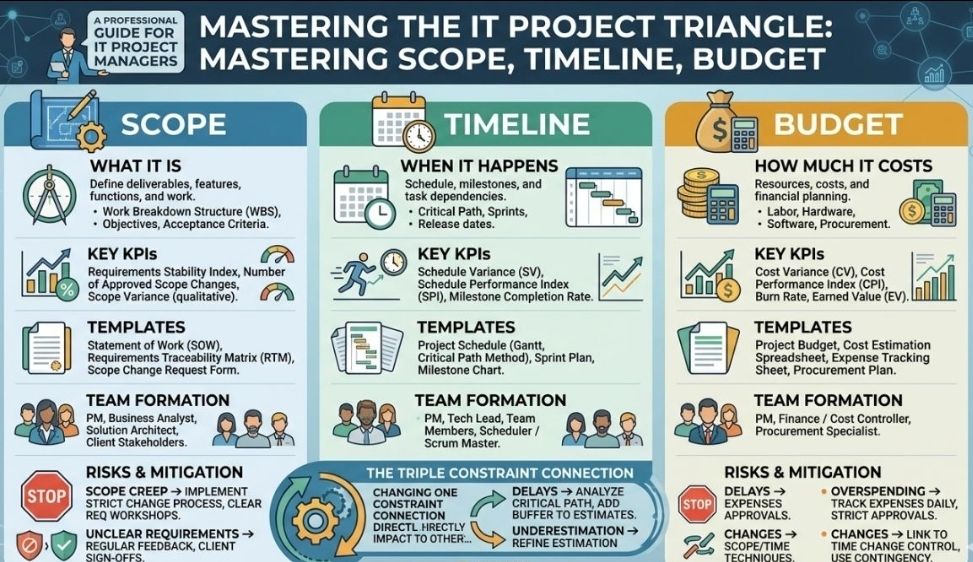
The best approach to writing a project plan breakdown is to use a top-down decomposition strategy centered on a Work Breakdown Structure (WBS). This technique methodically slices a complex, high-level project into smaller, manageable chunks called work packages, ensuring that nothing is missed.
To build a flawless, actionable project breakdown, you must establish the project’s foundation before dissecting it into individual tasks.
1. Define the Scope and Deliverables
Before diving into a micro-level breakdown, you must know what you are building—and what you are not building.
Write a scope statement: Document the final outcomes, project boundaries, and explicit exclusions to prevent scope creep.
Identify major deliverables: Determine the high-level milestones or chunks of tangible value that must be completed.
Apply the 100% rule: The Project Management Institute (PMI) notes that your WBS must include 100% of the internal, external, and interim project management work.
2. Structure the Levels of Decomposition
A good project plan breakdown uses hierarchical tiers. Do not mix daily tasks with macro phases. Instead, follow a logical breakdown hierarchy:
Level 1 (The Project): The overall project objective or final product.
Level 2 (Phases or Major Deliverables): Broad operational segments (e.g., Initiation, Design, Development, Testing).
Level 3 (Sub-deliverables): Specific components within a phase (e.g., under Development, you might have Frontend Architecture).
Level 4 (Work Packages): The lowest level of the WBS. These are discrete items that can be assigned to a specific team or individual and estimated for time and budget.
3. Apply the 80-Hour Rule
When decomposing down to the task level, determine how granular you need to be by tracking effort, not just calendar time:
The 80-hour threshold: A single work package should take no more than 80 hours (two weeks of full-time work) and no less than 8 hours to complete.
Avoid micro-management: If a task takes less than 8 hours, group it with others. If it exceeds 80 hours, it is too complex and needs to be broken down further.
4. Build a WBS Dictionary
A visual chart or list is helpful, but context prevents mistakes. For each work package at the bottom of your hierarchy, document:
Task description: Clear language outlining what “done” actually looks like.
Assigned owner: One single person or team responsible for the execution.
Pre-requisites and dependencies: Clarify which tasks must finish before the next can begin.
5. Sequence, Estimate, and Schedule
Once the work is broken down, pull it into a working chronological timeline using software like Microsoft Project (see MS .mpp templates in website banner), Asana or Monday.com.
Sequence activities: Map the chronological order and identify the critical path—the longest string of dependent tasks.
Estimate duration & resources: Gather the actual people doing the work to estimate time, capacity, and material needs realistically.
Add contingency: Factor in safety buffers to protect the project baseline from unexpected delays.
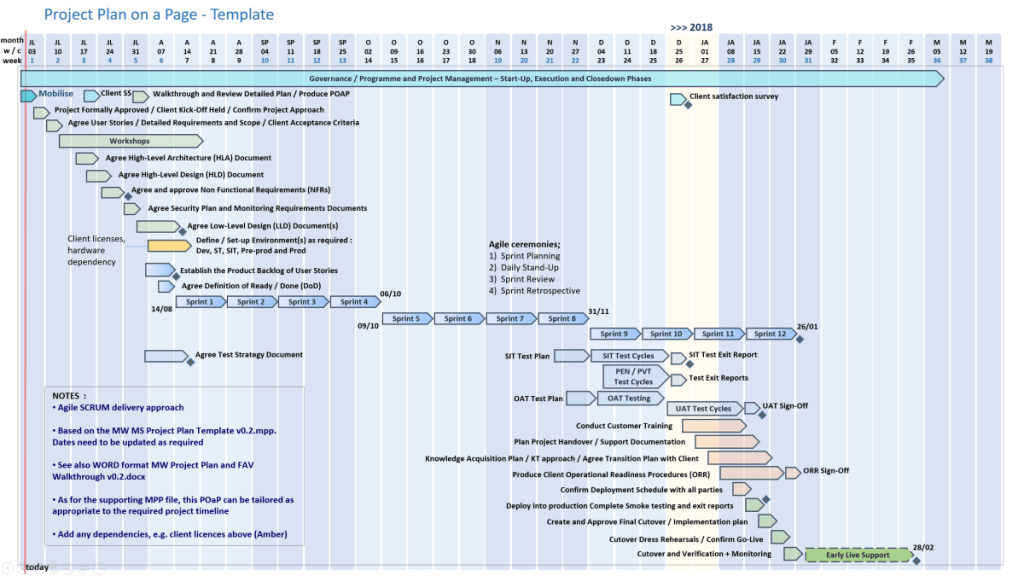
Microsoft Project is a powerful project management software used to plan, schedule, and oversee tasks, resources, and deadlines. Its native .mpp file format supports building Work Breakdown Structures (WBS), calculating critical paths, allocating resources, and monitoring project budgets within the Microsoft ecosystem.
Configuring a high-quality .mpp plan requires a systematic approach to ensure schedule accuracy and prevent logic errors. Follow this step-by-step methodology to build a robust plan:
1. Project Initialization
Set Project Information: Go to the Project tab, click Project Information, and define your Start Date. Ensure the scheduling is set to start from this date rather than a “Current Date” override.
Define Working Calendars: Adjust your project’s default calendar for weekends, statutory holidays, and company non-working time so the timeline accurately reflects actual working days.
Configure Default Scheduling: Go to File > Options > Schedule and set New tasks created to Auto Schedule. This ensures your tasks respond automatically to changes in predecessors and durations.
2. Work Breakdown Structure (WBS)
Brainstorm Task Lists: Before entering dates, list all project deliverables and normal tasks in the Gantt Chart view.
Apply Hierarchy: Use the Indent/Outdent features to organize tasks into major phases (Summary Tasks) and actionable subtasks (Work Packages).
Create Milestones: Set the duration of key deliverable completions or approval gates to 0 days to act as clear checkpoints on your timeline.
3. Task Dependencies & Logic
Establish Relationships: Link tasks in logical sequences (e.g., using Finish-to-Start relationships). Every task—except the very first one in the project—must have a predecessor.
Never Link Summary Tasks: Only link the lowest-level subtasks. Linking summary task bars introduces circular logic errors and unpredictability.
Avoid Hard Constraints: Do not type specific dates into the Start/Finish columns unless absolutely mandatory. Doing so creates “Must Start On” constraints that break the critical path when upstream tasks are delayed.
4. Resource Allocation
Setup the Resource Sheet: Navigate to the Resource Sheet and add all resources required to do the work, defining their standard rates, maximum capacities (e.g., 100% availability), and calendars.
Assign Resources: Return to the Gantt Chart and assign specific work resources (people) to corresponding tasks. This helps Microsoft Project calculate total effort and spot resource overallocations.
Resource Leveling: Use the built-in Resource Leveling feature to automatically adjust assignments and resolve conflicts when team members are overcommitted.
5. Finalizing and Tracking
Set a Baseline: Once the plan has been reviewed and approved by stakeholders, go to Project > Set Baseline. This captures a snapshot of your original scope, Start, Finish, Cost, and Work fields.
Set the Status Date: When recording progress, always set the Status Date to today’s date before entering percentage completions.
Project risks are uncertain events that, if they occur, can impact a project’s objectives. They are generally broken down into core categories: financial, technical, schedule, operational, and external. Proper risk assessment evaluates the probability and impact of these threats to prioritize mitigation strategies.
Detailed Risk Breakdown
1. Financial Risks
These risks relate to project budgets, funding cuts, and cash flow.
Cost Overruns: Expenses exceeding the allocated budget.
Funding Delays: Cash flow interruptions from sponsors or clients.
Currency Fluctuations: Affecting purchasing power for international materials.
Severity:High/Critical. Can lead to project cancellation if not mitigated.
2. Technical Risks
Emerging from technology gaps, security vulnerabilities, or poor integration.
Technology Failures: Systems crashing or underperforming.
Software Bugs: Errors causing glitches or data corruption.
Security Breaches: Data theft or loss compromising privacy.
Severity:Medium to High. Can completely stall deliverables or undermine final quality.
3. Operational Risks
Internal workflow inefficiencies, process breakdowns, and human factors.
Resource Shortages: Missing key team members or materials.
Poor Communication: Siloed workflows leading to rework and mistakes.
Supply Chain Disruptions: Delays in procuring high-quality goods.
Severity:Low to Medium. Tends to erode timelines quietly but can escalate if left unmanaged.
4. Schedule Risks
Risks jeopardizing deadlines, causing timeline slippage or severe delays.
Scope Creep: Uncontrolled changes or continuous addition of project requirements.
1. Preparing for a Steering Committee, SteerCo2. Preparing for a Steering Committee, SteerCo
Also,
Preparing for a Steering Committee (SteerCo) means ensuring senior stakeholders are aligned, not surprised.
Share a concise pre-read 48–72 hours prior focusing on strategic updates, key risks, and necessary decisions. Use the meeting itself to seek guidance or arbitration rather than just reading through slides.
A successful SteerCo relies on keeping your presentation highly strategic. Here is an actionable checklist to prepare:
1. The Pre-Read (Distribute 2-3 Days Before)
One-Page Status Summary: A simple Red-Amber-Green (RAG) dashboard covering schedule, budget, and scope.
The “Ask”: Clearly outline the specific decisions or approvals you need from the committee.
No Surprises Rule: If there is a major blocker or budget overrun, brief key members individually before sending the formal pack.
2. The Presentation Structure
Executive Summary: Quick reminder of project goals, scope, and target timelines.
Project Progress: Highlight major milestones recently achieved.
Financial Health: Compare actual spend vs. planned budget.
Risks & Issues: Focus only on severe roadblocks and present actionable mitigation options.
Decisions Needed: State the options, pros/cons, and your recommendation.
3. During the Meeting
Focus on the Big Picture: Do not get bogged down in granular project details.
Manage the Politics: Be prepared for pushback and answer objectively. If you don’t know an answer, take an action item rather than bluffing.
Typical Agile Scrum Master interview questions evaluate your understanding of the Scrum Framework (the 3-5-3 structure), your ability to facilitate continuous improvement, and your soft skills in conflict resolution and servant leadership.
The questions generally fall into four core categories:
1. Scrum Fundamentals & Frameworks
These questions test your technical knowledge of Scrum and how it compares to other frameworks.
Explain Scrum vs. Agile: Agile is the overarching mindset and set of principles; Scrum is a specific, lightweight framework for implementing Agile.
The 3-5-3 structure: What are the three roles (Product Owner, Scrum Master, Developers), five events (Sprint, Sprint Planning, Daily Scrum, Sprint Review, Sprint Retrospective), and three artifacts (Product Backlog, Sprint Backlog, Increment)?
Scaling Agile: What experience do you have scaling Agile (e.g., SAFe, Scrum of Scrums, Nexus) if the organization is large?
2. Facilitation & Coaching
Interviewers want to see how you run events, coach Product Owners, and improve team delivery.
Daily Scrum: What is your approach to running the Daily Scrum, and how do you prevent it from becoming just a status update?
Retrospectives: What specific techniques or games do you use to keep retrospectives fresh and actionable?
Definition of Done (DoD): How do you help a team create and adhere to a clear Definition of Done?
Metrics: How do you track a team’s effectiveness (e.g., velocity, sprint goal success, cycle time, burndown charts)?
3. Behavioral & Situational Scenarios
These “tell me about a time when…” questions assess your real-world experience.
Team Conflict: Can you describe a time when you had to resolve a conflict between team members or between a developer and the Product Owner?
Resistant Teams: What would you do if a team member or stakeholder doesn’t see the value in Scrum ceremonies and refuses to participate?
Management Intervention: How do you handle managers or executives who try to bypass the Scrum process or assign work directly to the developers?
Scope Creep: How do you handle sudden mid-sprint requirement changes or scope creep?
4. Self-Awareness & Servant Leadership
Hiring managers ask these to test your humility and growth mindset.
Your Greatest Failure: Can you share a time you failed as a Scrum Master, and what you learned from the experience?
Protecting the Team: How do you say “no” to leadership or protect the team from external noise while still serving the broader organization?
__________
More Agile Scrum Questions with Example Answers:
Mastering a Scrum Master interview involves demonstrating a deep understanding of servant leadership, the Agile mindset, and hands-on experience navigating team dynamics. Below are the most common interview questions, summarized with strategic, industry-recommended answers to help you stand out.
Core Scrum Framework & Mechanics
Question 1: Explain the 3-5-3 structure of Scrum.
What they’re looking for: A solid foundation in Scrum basics.
Recommended Answer: “Scrum is governed by a ‘3-5-3’ rule: 3 roles (Product Owner, Scrum Master, Developers), 5 events (Sprint, Sprint Planning, Daily Scrum, Sprint Review, Sprint Retrospective), and 3 artifacts (Product Backlog, Sprint Backlog, Increment).”
Question 2: What is the difference between a Product Backlog and a Sprint Backlog?
What they’re looking for: Understanding of backlog management and scope.
Recommended Answer: “The Product Backlog is a continuously evolving, prioritized list of everything needed for the product, owned by the Product Owner. The Sprint Backlog is a subset of the Product Backlog—it’s the specific forecast of items the team commits to delivering during the current sprint.”
Behavioral & Situational Questions
Question 3: How do you handle conflict within the Scrum team?
What they’re looking for: Your facilitation and conflict-resolution skills, avoiding direct intervention where the team can self-manage.
Recommended Answer: “I avoid playing the role of a micromanager. Instead, I facilitate open dialogue and encourage the team to address the conflict directly using the Scrum values of openness and respect. My goal is to guide them to find a mutually agreeable solution while fostering an environment of psychological safety.”
Question 4: What do you do if a team member refuses to adopt Scrum practices?
What they’re looking for: Change management skills and patience.
Recommended Answer: “I first try to understand the root cause of their resistance, as it usually stems from a lack of understanding or fear of change. I would have a private one-on-one conversation to address their concerns. I might pair them with an experienced Agile advocate or use team-building exercises to demonstrate the value of Scrum in a low-pressure way.”
Leadership & Stakeholder Management
Question 5: Tell me about a time you had to challenge leadership or management.
What they’re looking for: The courage to protect the team’s focus and uphold Scrum principles.
Recommended Answer: “I once had a stakeholder attempt to bypass the Product Owner and directly assign high-priority tasks to Developers mid-sprint. I respectfully but firmly challenged this by explaining how breaking the Sprint Goal jeopardizes the team’s focus and the project’s overall velocity. I then helped the stakeholder work with the Product Owner to place the new task in the Product Backlog for the next sprint planning.”
Question 6: How do you measure if your team is truly Agile?
What they’re looking for: Focus on delivering value over measuring arbitrary metrics like velocity.
Recommended Answer: “Velocity is for planning, not for measuring success. I look at outcome-based metrics, such as Sprint Goal success rates, customer satisfaction scores, time-to-market, and the quality of increments. The ultimate measure is whether we are continuously delivering iterative business value to our end users.”
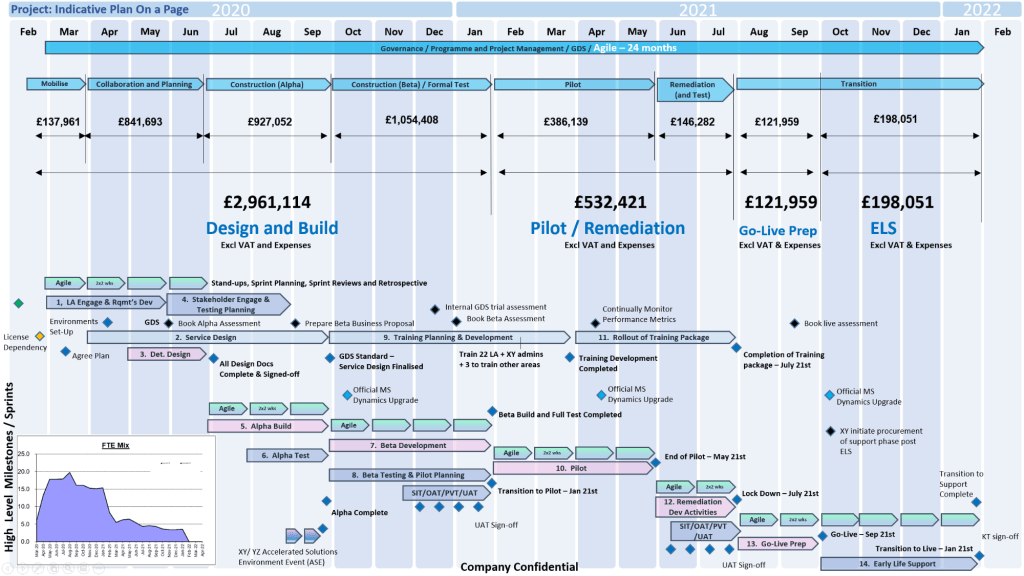
A Plan on a Page (POAP) is a concise, visual summary of a project’s core elements. It distills complex, granular project details into a highly accessible, single-page format.
It acts as an executive summary rather than a replacement for comprehensive, detailed project plans. Example, tailorable Agile and Waterfall MS PowerPoint POaP project templates can be purchased at this link.
Plan On a Page also known as a POAP
🎯 Primary Purpose
Executive Communication: Provides busy stakeholders and C-level management with rapid visibility into a project’s status without overwhelming them with data.
Alignment: Ensures teams, sponsors, and stakeholders share a unified understanding of project goals and direction.
Focus & Risk Management: Keeps the strategic vision front-and-center, prevents teams from getting “lost in the weeds,” and allows leaders to spot high-level risks early.
Decision Support: Serves as a quick reference guide during steering committee and status meetings.
A Plan on a Page (POAP) is a concise, visual summary of a project’s core elements
📝 Content Summary
To fit on a single page, a POAP strips away tactical daily tasks and focuses only on the most critical strategic and timeline components:
Project Vision & Scope: A concise statement of what the project aims to deliver.
Objectives & KPIs: Specific, measurable targets and Key Performance Indicators to measure success.
Visual Timeline: A high-level roadmap, Gantt chart, or phase-based breakdown (e.g., Discovery, Execution, Launch) displaying major milestones.
Project Health/Status: Current RAG (Red/Amber/Green) status or progress tracking.
Resource & Budget Allocation: High-level overview of assigned budget and key personnel.
Risk & Dependencies: Notable blockers, constraints, or critical assumptions.
Governance & Contacts: The project sponsors, managers, and the best way to get support.
All POAP templates can be purchased by clicking on the link on the website banner
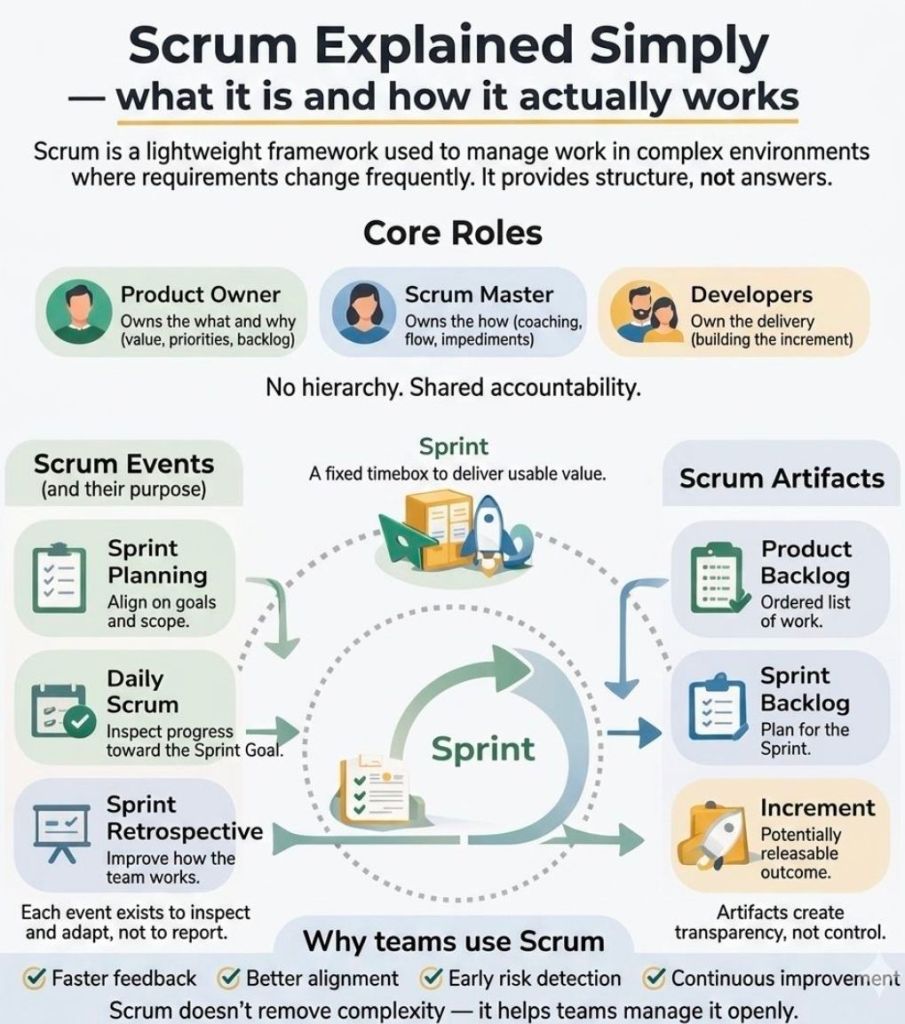
Agile is a project management philosophy, while Scrum is the structured, real-world framework used to put that philosophy into action. Think of Agile as a commitment to healthy living, and Scrum as the specific daily workout routine you follow to stay fit. Instead of planning a massive project from start to finish upfront, Scrum breaks the work down into small, manageable pieces delivered in short cycles.
The easiest way to understand Scrum is through the 3-5-3 Rule: 3 Roles, 5 Events, and 3 Artifacts.
👥 The 3 Roles
A standard Scrum team is small, cross-functional, and self-managing, meaning they have all the skills needed to complete the work without relying on outsiders.
Product Owner: The visionary. They understand customer needs, decide what needs to be built, and maintain the master to-do list.
Scrum Master: The coach. They do not manage the team; instead, they protect them from distractions, facilitate meetings, and clear roadblocks.
Developers: The builders. This includes the engineers, designers, or writers who do the hands-on work and decide how to build it.
📦 The 3 Artifacts
Artifacts are simply the tangible items or lists used to maintain transparency across the project.
Product Backlog: The ultimate master list of features, fixes, and requirements needed for the product, prioritized by value.
Sprint Backlog: The specific subset of items selected from the master list that the team commits to finishing during the current cycle.
Increment: The final, working piece of the product delivered at the end of a cycle that meets the team’s “Definition of Done”.
📅 The 5 Events (Ceremonies)
Scrum operates in time-boxed blocks called Sprints, which usually last 1 to 4 weeks. Each Sprint includes four distinct meetings:
The Sprint: The time-box itself where the actual building happens.
Sprint Planning: A meeting at the start of a Sprint where the team decides what they can realistically achieve and creates a plan.
Daily Scrum (Stand-up): A quick, 15-minute daily meeting where developers sync on progress, plan the next 24 hours, and flag blockers.
Sprint Review: A showcase held at the end of the Sprint to demo the working increment to stakeholders and gather feedback.
Sprint Retrospective: An internal team meeting to review what went well, what went wrong, and how to improve the process for the next Sprint.
🏗️ Why Does Scrum Work?
Scrum relies entirely on Empiricism, meaning making decisions based on real-world evidence rather than guesswork. It stands firmly on three pillars:
Transparency: Everyone involved sees exactly what is happening.
Inspection: The team frequently stops to check the quality of the product and progress.
Adaptation: If something goes off-course, the team shifts direction immediately rather than blindly following an outdated plan.
Mark Whitfield is an SC-cleared Senior IT Project and Engagement Manager with over 30 years of experience. His career spans from early mainframe programming to leading multi-million-pound cloud migrations and digital transformations for major financial, utility, and government clients.
The chronological breakdown of his professional project portfolio, structured by his definitive career eras, is detailed below:
1. The Technical Era (1990–1995)
During this foundational era, Mark worked as a Programmer and Lead Analyst for The Software Partnership (acquired by Deluxe Data in 1994). He focused strictly on the development, optimization, and deployment of the sp/ARCHITECT-BANK electronic banking solution on Tandem Mainframe Computers.
Details: Handled the custom design and backend coding for a high-profile desktop electronic business banking application.
Project: Automated Touch-Tone Phone Banking Suite
Year: 1992–1993
Client: Girofon (Denmark)
Budget: Client-retained vendor contract
Details: Coded automated, menu-driven voice solutions operating on a Periphonics VRAM device to fetch live customer balances directly from mainframes.
Project: Early Digital Inter-Account Transfers
Year: 1993–1994
Client: TSB & Bank of Scotland
Budget: Internal product development
Details: Directed logic design and mainframe coding to support pioneering inter-account electronic funds transfers.
Project: International Banking Optimization
Year: 1994–1995
Client: Rabobank
Budget: Vendor-driven custom development framework
Details: Managed localized software optimization, custom patches, and deployment testing for global banking operations.
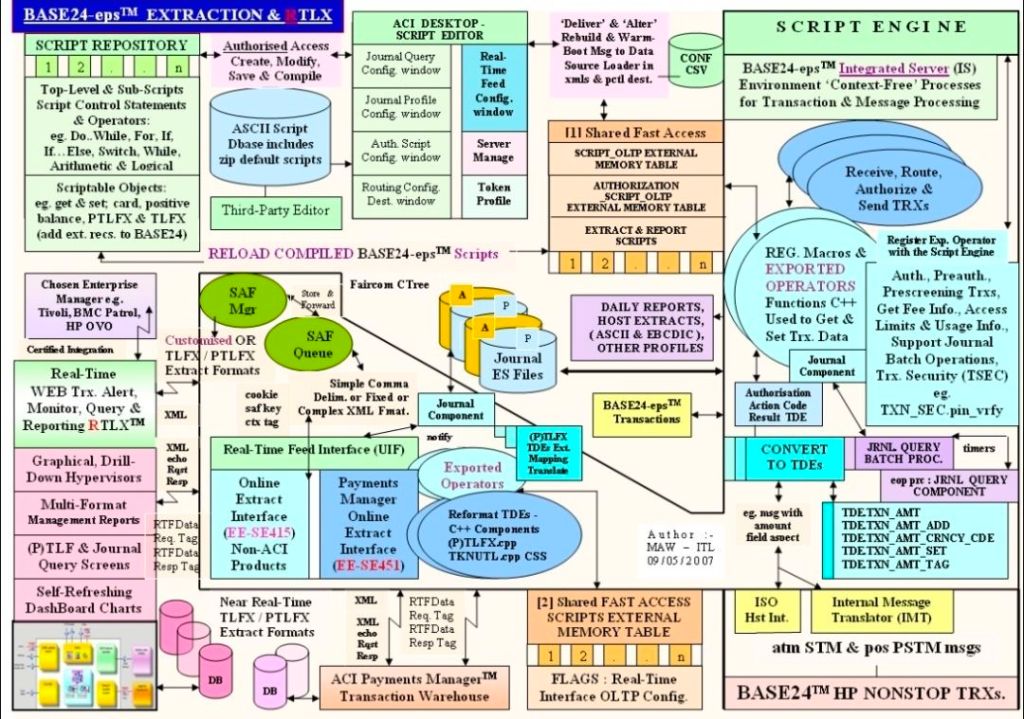
2. The Infrastructure & Monitoring Era (1995–2014)
Mark transitioned into a Product and Project Manager role at Insider Technologies Limited (and later a brief stint at Wincor Nixdorf). His focus shifted heavily toward platform diagnostics, high-availability transaction monitoring, and financial hardware software integrations.
Project: Reflex (Reflex 80:20) System Co-Development
Year: 1995–2004
Client: Multiple Tier-1 Investment Banks (including Euroclear/Crestco, Bank of England, and Deutsche Bank)
Budget: Part of a broader £3M Management Buyout (MBO) product portfolio
Details: Acted as Senior Programmer and Technical Lead to co-develop diagnostic monitoring modules for high-availability mainframes.
Details: Managed the integration of transaction tracking across ATM networks using ACI’s XPNET and HP NonStop architecture.
Project: Legacy ATM Software Modernisation
Year: 2013–2014
Client: Major UK Retail Bank (via Wincor Nixdorf Professional Services)
Budget: Corporate financial service transformation
Details: Served as Project Manager executing the swap-out of outdated, legacy ATM client systems for modernized software stacks.
3. The Digital and Cloud Era (2014–Present)
This era highlights Mark’s leadership of large-scale Agile and Waterfall digital delivery frameworks, moving from corporate gambling technology to complex, high-budget UK public sector programs.
Project: Mobile & Online Gaming Sportsbook Platforms
Details: Led Agile Scrum development teams to upgrade payment gateways, implement fraud detection, and roll out football/horse racing mobile interfaces.
Project: National Air Space Real-Time Mobile Applications
Year: 2016
Client: NATS (UK-wide Air Traffic Organisation)
Budget: Corporate custom applications initiative
Details: Managed the secure Agile delivery of Apple iOS applications displaying live military and public airspace information.
Project: Core Systems Interface Data Centre Migration
Year: 2016 (May–October)
Client: Royal Mail Group (RMG) / Postal Services
Budget:£4.3 Million
Details: Led a massive cross-functional team of 90 Capgemini engineers to migrate over 1,100 platform data interfaces ahead of peak annual trading.
Project: Automated Call Centre CCaaS Telephony Implementation
Year: 2017 (May onwards)
Client: Local Regional Government
Budget:£400,000
Details: Deployed a programmatic dialler system linked with Microsoft Azure CRM to facilitate the “Support for Mortgage Interest” campaign.
Project: Automotive Online Car Sales and Digital Readiness
Year: 2017 (October)
Client: Jaguar Land Rover (JLR) / Aston Agile Delivery Centre
Budget:£1.1 Million (Split into a £670k Customer Sales Portal and a £430k Readiness project)
Details: Engagement Manager implementing a new-car ecommerce vehicle pipeline.
Budget:£1 Million+ (Part of a larger £13.5M cloud program moving 130 apps)
Details: Orchestrated the launch and configuration of Azure Cloud frameworks migrating 12 historical Dynamics 2016 platforms to Dynamics 365 Online.
Project: Fish Export Service (FES) to CHIP Inspection Portal
Year: 2023–2024 (Nov–Feb)
Client: UK Government / Northern Ireland Trading Framework
Budget:£1 Million+
Details: Served as Technical Delivery Manager directing Agile Scrum teams to build cloud-hosted APIs supporting catch verification under the Windsor Framework.
Centiun is a UK-based Microsoft AI Cloud Partner and IT consultancy specializing in digital transformation, cloud migration, and AI integration for public and private sector organizations.
Centiun is a UK-based Microsoft AI Cloud Partner and IT consultancy
They help businesses modernize operations, leverage low/no-code platforms, and transition legacy infrastructure to secure cloud environments.
Core Services
Cloud & App Modernization: Migrating on-premise, legacy applications to secure cloud environments to reduce costs and enhance agility.
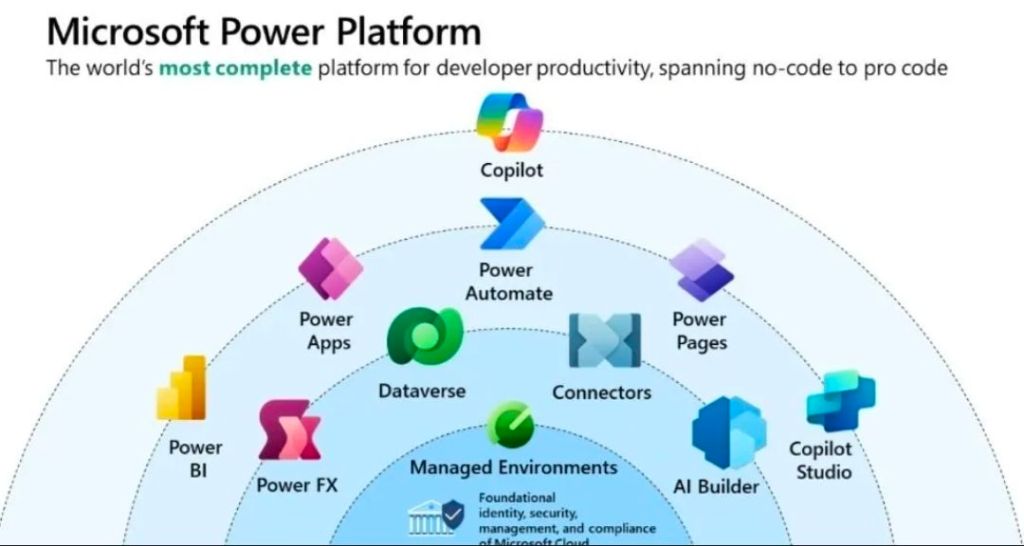
Microsoft AI & Business Applications: Implementing solutions across the Microsoft stack, including Copilot, Power Platform, and Dynamics 365, to improve process efficiency and data-driven decision-making.
Managed Services & Governance: Providing SLA-compliant technical governance, threat monitoring, and support to ensure business continuity.
Training & Enablement: Upskilling staff to confidently use Microsoft tools and low-code solutions.
Target Industries
Centiun tailors their technology solutions to several specialized sectors, offering domain expertise in:
Healthcare and Non-profits
Public Bodies and Central Government
Financial Services and Manufacturing
Energy and Utilities
Why They Stand Out
Microsoft Expertise: Their seasoned experts hold numerous Microsoft certifications and boast a combined 20+ years of experience in Microsoft Business Applications.
Tailored Approach: They focus on personal service rather than one-size-fits-all solutions, aiming to help clients scale and modernize while minimizing operational disruption.
Security & Trust: The firm operates with strict data security measures, holding accreditations like Cyber Essentials and registration with the Information Commissioner’s Office (ICO).
Explore their complete list of solutions and case studies directly on the Centiun Official Website.
Agile project management is an iterative, adaptive approach that breaks projects down into small, manageable cycles called sprints or iterations. Instead of planning the entire project upfront, teams continuously deliver functional increments, gather immediate feedback, and adapt to changing requirements. It prioritizes team collaboration, customer involvement, and rapid value delivery over rigid documentation and sequential phases.
Comprehensive Timeline Breakdown by Era and Year
Era 1: The Foundational Seeds (1950s – 1980s)
Before “Agile” existed as a formal term, engineers and researchers laid the groundwork through lean manufacturing and early iterative computing.
1957: IBM begins utilizing incremental development concepts under Gerald M. Weinberg.
1958: Software for Project Mercury (NASA’s first human spaceflight program) is developed using rapid half-day iterations.
1970: Dr Winston Royce publishes a paper describing the Waterfall methodology. Paradoxically, he presents it as high-risk, yet it becomes the dominant, rigid corporate framework for decades.
1980: Toyota refines “Just-In-Time” logistics and visual management system concepts, which later directly inspire Kanban and Lean software practices.
1986: Authors Hirotaka Takeuchi and Ikujiro Nonaka publish “The New New Product Development Game” in the Harvard Business Review. They introduce a holistic, “rugby-style” team approach, coining the term “Scrum”.
1988: Dr Barry Boehm introduces the Spiral Model, formalizing risk-driven, iterative lifecycle planning.
Era 2: The “Lightweight” Revolt (1990s)
Driven by frustration over the high failure rates and slow delivery of Waterfall, software pioneers independently build faster, more flexible frameworks.
1991: James Martin formalizes Rapid Application Development (RAD), highlighting timeboxing, prototyping, and active customer involvement.
1993: Jeff Sutherland, John Scumniotales, and Jeff McKenna deploy the very first operational Scrum process at Easel Corporation.
1994: The Dynamic Systems Development Method (DSDM) is launched in the UK, providing one of the earliest structured frameworks for iterative project delivery.
1995: Ken Schwaber and Jeff Sutherland co-present the formal Scrum Framework to the public at the OOPSLA conference.
1996: Kent Beck introduces Extreme Programming (XP), introducing core engineering mechanics like pair programming and test-driven development (TDD).
1997: Jeff De Luca and Peter Coad design Feature-Driven Development (FDD) to focus strictly on client-valued functional results.
Era 3: The Manifesto Moment (2000 – 2001)
The pivotal pivot point where separate iterative movements unite into a single, cohesive global movement.
2000: Pre-meeting alignment occurs. Martin Fowler publishes his definitive article on Continuous Integration (CI), and Extreme Programming teams begin adopting Scrum’s three-question daily standup format.
February 2001: The Agile Manifesto is Born. Seventeen software development pioneers meet at a ski resort in Snowbird, Utah. They discover common ground, author the Manifesto for Agile Software Development, and establish the 4 Core Values and 12 Principles.
Late 2001: The Agile Alliance non-profit is established to safeguard, evolve, and distribute Agile education globally.
Era 4: Mainstream Adoption & Scaling (2002 – 2019)
Agile shifts from a rebellious IT trend into a standard corporate expectation, requiring frameworks that can scale across massive enterprises.
2002: Ken Schwaber co-founds the Scrum Alliance to offer standardized certifications (like Certified ScrumMaster), dramatically accelerating global adoption.
2003: Mary and Tom Poppendieck publish Lean Software Development, cleanly mapping Toyota’s manufacturing efficiencies directly onto digital projects.
2009: The Software Craftsmanship Manifesto is created to ensure technical excellence and code quality are not forgotten during rapid business sprints.
2011: Dean Leffingwell releases the Scaled Agile Framework (SAFe), allowing massive corporate enterprises to align hundreds of agile teams across entire portfolios.
2015: Global project management authorities officially pivot; AXELOS releases PRINCE2 Agile, and the Project Management Institute (PMI) introduces Agile certifications into its core curriculum.
Era 5: Modern Continuous Agility (2020s – Present)
Agile transcends IT entirely, cementing its place as an overarching organizational strategy for business survival in an uncertain world.
2020: The Scrum Guide receives its most significant structural update, streamlining language, eliminating prescriptive micro-management, and focusing intensely on a single, unified team working toward a singular “Product Goal”.
2021–2023: Business Agility explodes. Non-technical departments—including HR, Marketing, Legal, and Finance—broadly restructure their workflows into iterative agile backlogs to manage volatile hybrid work environments.
2024–Present: AI-Driven Agility becomes standard practice. Project management tools use generative AI to automatically draft user stories, estimate team velocity, and dynamically rewrite project sprint backlogs based on real-time market shifts.
SAFe (Scaled Agile Framework) events are structured, time-boxed ceremonies designed to drive synchronization, alignment, and continuous improvement across different levels of an enterprise.
These events are primarily categorized into Team-level events (which mirror standard Scrum practices) and Agile Release Train (ART) level events (which orchestrate multiple teams working toward a shared goal).
The core events within Essential SAFe are broken down below by organizational layer.
👥 Agile Team-Level Events
These recurrent ceremonies occur inside a short timebox called an Iteration (typically lasting 2 weeks) and focus on local execution.
Iteration Planning: Teams refine the iteration plan, select backlog stories, and commit to a set of Iteration Goals.
Team Sync (Daily Stand-up): A brief, daily 15-minute meeting where team members align on progress, discuss daily goals, and highlight impediments.
Iteration Review: A cadence-based showcase at the end of the iteration where teams demo working software to gather immediate feedback.
Iteration Retrospective: Held at the end of each iteration to reflect on the process, team dynamics, and behaviors to drive relentless improvement.
Backlog Refinement: A weekly meeting where the Product Owner and team flesh out, estimate, and prep user stories for upcoming iterations.
🚊 Agile Release Train (ART) Level Events
These higher-level events drive the Planning Interval (PI), an 8 to 12-week timebox where an entire “train” of 5–12 teams delivers cross-functional value.
PI Planning: The multi-day flagship event of SAFe where all teams, stakeholders, and leaders align on a shared business vision, map dependencies, and commit to PI objectives.
System Demo: A regular event occurring every iteration where the integrated functionality built by the entire ART is demonstrated to stakeholders for feedback.
Coach Sync (formerly Scrum of Scrums): Facilitated by the Release Train Engineer (RTE), Scrum Masters meet to resolve cross-team dependencies, risks, and progress hurdles.
PO Sync: Product Owners and Product Management meet to track milestone progress, manage scope adjustments, and ensure the train remains aligned with business goals.
ART Sync: A combined session of Coach Sync and PO Sync used to streamline communication regarding execution and deployment.
Inspect & Adapt (I&A): A major event held at the end of the PI consisting of a system demo, quantitative measurements, and a problem-solving workshop to implement systemic backlog improvements.
Summary of Differences
For a quick comparison, you can look at how responsibilities scale across the framework:
SAFe (Scaled Agile Framework) events are structured, time-boxed ceremonies designed to drive synchronization, alignment, and continuous improvement across different levels of an enterprise
Mark Whitfield is an SC-cleared Senior IT Project Manager with over 30 years of experience delivering high-availability financial, cloud, and digital transformation projects. Over his career, he has transitioned from deep technical engineering on HPE NonStop (Tandem) mainframe systems to leading major corporate and public sector Agile and Waterfall software rollouts.
A comprehensive, year-by-year timeline breakdown of his project history and clients since 1990 is outlined below.
💻 The Technical Era (1990–1995)
During this period, Whitfield worked as a Programmer and Lead Analyst for The Software Partnership (acquired by Deluxe Data in 1994). He focused on electronic banking software (sp/ARCHITECT-BANK) on Tandem Mainframe Computers.
1990–1992: Barclays Bank – Placed on-site at Knutsford, Cheshire to design and code software for the high-profile Barclays Business Master II (BBM II) electronic desktop banking project.
1992–1993: Girofon (Denmark) – Developed a touch-tone phone banking suite. This allowed clients to use automated voice/menu-driven systems via a Periphonics VRAM device to fetch live balances from back-end mainframes.
1993–1994: TSB & Bank of Scotland – Conducted early-era digital investigations, logic design, and mainframe coding for inter-account desktop money transfers.
1994–1995: Rabobank – Headed software optimization, custom electronic coding patches, and on-site deployment validation for international operations.
🛡️ Monitoring & Infrastructure Era (1995–2013)
Whitfield joined Insider Technologies Limited (ITL) in Salford Quays, specializing in platform diagnostics, transaction monitoring, and financial logging systems for mission-critical infrastructure.
1995–1996: Internal ITL Product R&D – Core developer on the Reflex monitoring suite (Reflex 80:20), creating platform health and diagnostic plug-in modules.
1997–1998: CRESTCo (now Euroclear) – Brought in as a technical infrastructure consultant to run benchmark tests on newly released Tandem S7000 processing hardware nodes.
1999–2001: Bank of England / Deutsche Bank – Deployed real-time tracking protocols utilizing ITL’s MultiBatch scheduling architectures and file monitors.
2002–2003: Hewlett-Packard (HP) – Successfully managed the rigorous certification process for the first HP OpenView Operations (OVO) Smart Plug-In built for the NonStop mainframe environment.
2008–2010: Saudi Arabian Retail Bank – Acted as Project Manager overseeing the cross-border rollout of a high-volume ATM and Point-of-Sale (POS) monitoring system.
2011–2013: Global Payments / Standard Chartered – Integrated transaction monitoring capabilities with external corporate frameworks such as TIVOLI and XPERT24 using ACI’s XPNET architecture.
This timeframe marked a total transition into senior contract project management, dealing directly with multi-million-pound programs.
2013–2014: Lloyds Banking Group (LBG) – Augmented into Wincor Nixdorf as the IT Project Manager leading a £5+ million workstream. This was part of LBG’s comprehensive Self-Service Software Replacement (SSSR) initiative to modernise legacy ATM software.
2014–2016: Betfred – Senior IT Project Manager inside an Agile Scrum structure. Directed cross-functional software vendors to deliver updates for mobile apps (iOS/Android), fraud detection systems, and payment gateways for their digital sportsbook platforms.
In January 2016, Whitfield joined global consultancy firm Capgemini as a Senior client-facing Engagement/Delivery Manager.
2016–2017: Aerospace & Defence Client – Managed an enterprise-level integration project to deploy a Salesforce-driven Single Customer View (SCV) portal platform.
2017–2018: Jaguar Land Rover (JLR) – Served as Project Manager for the iFAB Middleware Project, a complex 12-month architecture development program linking global manufacturing supply components.
2018–2019: MuleSoft (A Salesforce Company) – Augmented directly into MuleSoft’s London headquarters as a Delivery Manager, spearheading API-led connectivity deployments via the Anypoint Platform.
2019–2021: UK Government Agency (UK Gov) – Commanded a major Hybrid Cloud Migration initiative to refactor, re-host, and re-platform 130 legacy agency software applications directly to cloud servers.
2022: UK Utility Sector (Welsh Water / Scottish Water) – Dual-management lead executing a £0.5 million contract to migrate an aging, on-premise document management program (EQS) onto the Microsoft Azure cloud via Enablon.
2023–2026: Public Sector & Core Tooling (Current) – Managing high-value middleware and API integrations for entities like the Royal Mail Group (RMG), NATS, and regional government bodies. Concurrently authors a widely used portfolio of commercial project management templates (RAID logs, RACI matrixes, and MS Project MPP layouts) published via PROject Templates.
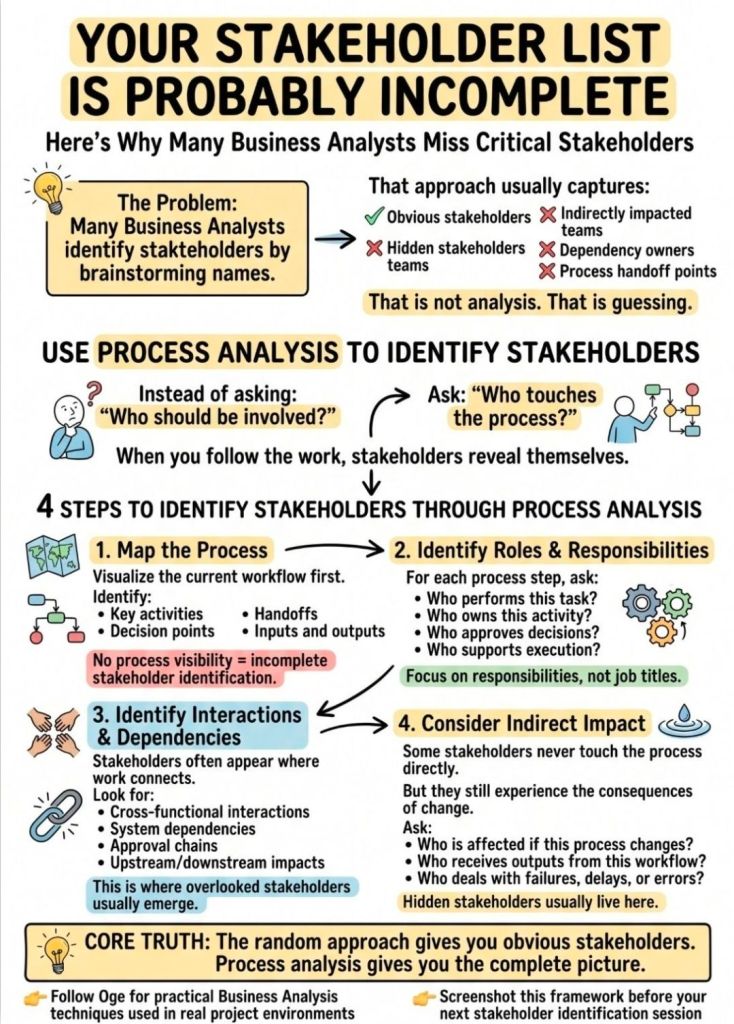
Completing the Stakeholder List using Process Analysis
Completing a stakeholder list using process analysis involves tracing the end-to-end lifecycle of a process to identify every individual, team, or organization that interacts with, influences, or is impacted by it. This ensures no hidden users, bottlenecks, or approvers are missed.
A four-step approach will ensure your list is thorough and actionable:
1. Map the Process Flow
Create a step-by-step flowchart of the current or future process. Break it down into key phases: Inputs, Activities, Outputs, and Outcomes. This visual map acts as a blueprint to spot every touchpoint where someone is involved.
2. Identify Stakeholders at Each Touchpoint
Go through each phase of your process map and ask the following dependency questions to pinpoint roles:
Input Stage: Who supplies the data, materials, or funding? (e.g., vendors, regulators, finance departments)
Activity Stage: Who performs the work or oversees it? (e.g., project teams, department managers, QA testers)
Output Stage: Who receives the final deliverable? (e.g., end-users, clients, customers)
Outcome Stage: Who is affected by the long-term results? (e.g., the community, executives, maintenance teams)
3. Classify and Prioritize
Once your comprehensive list is built, categorize stakeholders using the Power/Interest Matrix. This helps allocate your engagement efforts efficiently:
High Power, High Interest: Manage closely and collaborate heavily (e.g., Project Sponsors, Product Owners).
High Power, Low Interest: Keep satisfied but do not over-communicate (e.g., Regulators, Steering Committees).
Low Power, High Interest: Keep informed and consult regularly (e.g., End-users, Support Staff).
Wincor Nixdorf was a premier global provider of IT solutions, hardware, software, and services tailored for retail banks and the retail industry.
Headquartered in Paderborn, Germany, the company historically commanded roughly 35% of the global automated teller machine (ATM) market and stood as a dominant force in electronic point-of-sale (EPOS) systems.
Its operations focused deeply on business process optimisation, automated cash handling, and retail self-checkout systems. In 2016, Wincor Nixdorf merged with its US rival Diebold, Inc., creating the modern consolidated market leader, Diebold Nixdorf.
Detailed Historical Timeline
The history of Wincor Nixdorf spans several distinct strategic eras, tracing its evolution from a post-war calculator workshop into a modern global fintech titan.
Era 1: The Founding & Decentralised Computing (1952–1989)
This era was defined by entrepreneur Heinz Nixdorf, who pioneered small-to-medium business computing and electronic banking terminals across Europe.
1952: Heinz Nixdorf establishes Labor für Impulstechnik in Paderborn, Germany. The small enterprise builds electronic calculators for businesses rebuilding in post-war Europe.
1964: The company shifts from acting as a third-party component supplier to marketing office calculators and billing systems under its own brand name. []
1968: Following corporate acquisitions, the company officially rebrands as Nixdorf Computer AG and develops some of the world’s earliest decentralized minicomputers.
1969: The firm enters the North American market by purchasing the electronics division of the US office equipment manufacturer Victor Comptometer.
1971: Secures its first landmark international banking contract, supplying 1,000 terminals to the Swedish banking industry.
1978: Global sales cross DEM 1 billion, and the workforce grows to over 10,000 employees globally.
1982: Expands its engineering breadth by forming a dedicated corporate telecommunications division.
1984: Launches its initial public offering (IPO), floating shares publicly on the Frankfurt Stock Exchange.
1986: Founder Heinz Nixdorf suddenly dies of a heart attack at a corporate event. The company struggles to pivot from hardware-locked minicomputers to emerging open personal computer architectures.
1989: Amid intensifying global hardware margins and strategic missed steps, corporate financial losses top DEM 1 billion.
Era 2: The Siemens Integration & Corporate Carve-Out (1990–1998)
During this stage, corporate giant Siemens rescued and absorbed the distressed business, later reorganizing its retail and banking assets into a specialized standalone vehicle.
1990: Siemens AG steps in to purchase the shares of Nixdorf Computer AG, officially merging it with its own Data Information Services division to create Siemens Nixdorf Informationssysteme (SNI) AG.
1992: SNI expands heavily across European IT markets, operating as a distinct, specialized computing arm under the Siemens umbrella.
1996: Becomes the largest IT company in Germany and the second largest across the European continent.
1998: Siemens restructures its computing strategy; it sells its personal computer division to Acer and spins off the highly profitable banking and retail segments into a new unit: Siemens Nixdorf Retail and Banking Systems GmbH.
Era 3: Private Equity Buyout & The Rise of Wincor Nixdorf (1999–2015)
This period marked the official birth of the independent “Wincor Nixdorf” brand, characterized by aggressive global expansion, software-driven solutions, and public market listing.
1999: Private equity firms Kohlberg Kravis Roberts (KKR) and Goldman Sachs Capital Partners complete a buyout of the Siemens unit. The company is formally renamed Wincor Nixdorf GmbH.
2000: Launches major end-to-end IT outsourcing and infrastructure managed services alongside its standard terminal hardware.
2004: On 19 May, Wincor Nixdorf successfully returns to the public markets, listing as Wincor Nixdorf AG on the Frankfurt Stock Exchange via a high-performing IPO.
2006: Longtime Chief Executive Officer Karl-Heinz Stiller resigns from the board, leaving a structurally sound company expanding deep into automated cash recycling and software.
2009–2014: Deploys multi-vendor banking software and automated checkout machines worldwide, expanding operations across roughly 100 countries.
2015: Reports global revenues of €1.8 billion, split roughly 65% in banking services and 35% in retail point-of-sale solutions. On 23 November, US rival Diebold announces a formal business combination agreement to acquire the company.
Era 4: The Diebold Nixdorf Consolidation (2016–Present)
This current era represents the unification of American and European ATM powerhouses to navigate shifting brick-and-mortar financial landscapes.
2016: Diebold Inc. officially completes its $1.8 billion voluntary public takeover of Wincor Nixdorf AG on 15 August. The consolidated global giant begins unified operations as Diebold Nixdorf on 16 August.
2017: The UK Competition and Markets Authority (CMA) formally clears the merger following a comprehensive antitrust review, requiring Diebold to divest its legacy UK customer ATM operation to avoid localized market monopoly.
2021: Capitalizing on self-checkout shifts accelerated by the pandemic, the combined entity launches its next-generation DN Series™ EASY self-service retail product line.
2023: Burdened by legacy debt structures, supply chain disruptions, and pandemic operational challenges, Diebold Nixdorf files for a prepackaged Chapter 11 bankruptcy protection in June. The restructuring swiftly sheds $2.1 billion in debt. By August, it successfully emerges from bankruptcy, resuming trading on the New York Stock Exchange (NYSE).
2024–2026: The restructured firm shifts its focus from low-margin hardware to high-margin managed services and cloud software, stabilizing its global operations with annual revenues reaching $3.75 billion.
A Capgemini Engagement Manager is a senior-level, client-facing role responsible for end-to-end delivery of complex business and technology transformation programs. They bridge strategy and execution, acting as a trusted advisor to clients while maintaining operational and financial control over projects.
Engagement Manager, from 2016
Key Responsibilities
End-to-End Delivery: Overseeing projects from start to finish, ensuring milestones, SLAs, and contractual obligations are met on time and within budget.
Stakeholder Management: Acting as the primary client point of contact while aligning cross-functional and globally distributed delivery teams.
Risk & Governance: Identifying potential roadblocks, proactively managing risks, and ensuring strict adherence to project governance standards.
Business Growth: Spotting opportunities for additional business and supporting bid activities for account expansion.
Mark Whitfield, Engagement Management EM Level 2 Exam Passed 2017
Ideal Candidate Profile
Experience: Typically requires a degree in Business, Engineering, or IT, combined with at least 5+ years of experience in project management or service delivery within a B2B environment.
Skills: Strong commercial acumen, proficiency in formal methodologies (e.g., Agile, ITIL), and the ability to lead diverse, multinational teams.
C&CA UK’s Communications & Engagement Award Winner 2022, Cloud & Custom Applications, Mark Whitfield
Mark Whitfield, an SC cleared Senior Project Manager based in the Manchester area, has over 30 years of experience transitioning from a software engineer to an IT program leader.
His extensive technical and project management training spans methodologies, cloud infrastructure, and software applications.
A detailed breakdown of his training, certifications, and academic background includes:
Project Management Methodologies
PRINCE2 Practitioner: Certified via the ILX Group.
Agile SCRUM: Trained in-house with RADTAC.
Advanced Engagement Management: Level 2 certification completed via Capgemini.
Project Fundamentals: Completed “Fundamentals of Successful Project Management” and “Managing Multiple Projects” via Skillpath.
Microsoft Project: Microsoft Project ’98 certified.
Technical & Cloud Training
Microsoft Azure: AZ-900 Microsoft Certified Azure Fundamentals.
MuleSoft: Completed outcome-based delivery training and is a specialized Delivery Manager.
Technical Programming: Includes foundational database and software language training, such as C++ and MS SQL 2000 query training, as well as VPS and Tandem (HPE NonStop) technical/development courses.
Productivity: Completed Microsoft Excel Refresher and Expert skills training (Udemy and Microsoft).
Formal Education
Higher National Diploma (HND): Graduated with a Distinction (top) in Computing (1990).
Mark Whitfield invested many years in the HPE NonStop field from 1990. The HPE NonStop architecture (originally Tandem Computers) is a legendary fault-tolerant system known for 100% continuous availability. The platform’s hardware and software execution evolved across six distinct eras and processor transitions:
Architecture: The foundational “shared-nothing” parallel architecture. Featured redundant components (processors, disks, power supplies) connected by a proprietary dual-bus (Dynabus). The operating system provided instant automated failover.
Architecture: Expanded into 32-bit computing. To keep pace with industry performance, Tandem transitioned from proprietary processors to off-the-shelf MIPS RISC processors while heavily emulating the original instruction set for compatibility.
3. The Himalaya/ServerNet Era (1997–2004)
Years: 1997–2004
Processors: MIPS R-series
Architecture: Replaced the legacy Dynabus with ServerNet, a high-speed system interconnect that served as an early precursor to modern networking fabrics. (Compaq acquired Tandem in 1997, which subsequently merged with HP in 2002).
4. The Integrity Itanium Era (2005–2013)
Years: 2005–2013
Processors: Intel Itanium (TNS/E)
Architecture: Branded as HP Integrity NonStop (NonStop i). The platform moved off proprietary silicon to standard Intel Itanium processors. This was driven by the “NonStop Advanced Architecture” (NSAA), lowering hardware costs while maintaining Availability Level 4 (AL4) standards.
5. The NonStop X (x86-64) Era (2014–Present)
Years: 2014–2026
Processors: Intel Xeon x86-64 (TNS/X)
Architecture: Fully decoupled the OS from proprietary hardware by shifting to standard Intel x86-64 processors and InfiniBand fabric. The latest compute nodes (such as the NS5 X5 and NS9 X5) utilize modern Intel Xeon Scalable processors to maintain maximum Availability Level 4 (AL4) workloads.
6. The Virtualized NonStop Era (Present)
Years: 2015–Present
Processors: Virtual Machines / Cloud / x86
Architecture: HPE extended the platform to support Virtualized NonStop Software, allowing fault-tolerant enterprise workloads to run entirely in private clouds via standard VMware or hybrid architectures, independent of specific physical servers.
While all three roles fall under the “Business Analyst” umbrella, they differ in their primary focus: Functional BAs translate business needs into user requirements, Technical BAs focus on system architecture and integration, and Product BAs drive the product’s market value and long-term strategy.
1. Functional BA (The ‘Business’ Translator)
The Functional BA acts as the primary bridge between business stakeholders and the IT delivery team. They focus on what the business needs to achieve and how users will interact with the system.
Core Focus: Business processes, stakeholder communication, and end-user experience.
Day-to-day Responsibilities: Gathering requirements, mapping out user journeys, defining acceptance criteria, and creating process flow diagrams.
Key Skills: Stakeholder management, requirements elicitation, and deep domain knowledge (e.g., finance, healthcare).
2. Technical BA (The ‘System’ Architect)
The Technical BA bridges the gap between the functional requirements and the software development team. They focus on how the system will be built, ensuring the proposed solution is technically feasible, scalable, and secure.
Core Focus: System architecture, data flow, integrations, and non-functional requirements (like performance).
Day-to-day Responsibilities: Defining API structures, mapping data models, documenting system interfaces, and writing complex technical user stories.
Key Skills: Understanding of system integrations, database structures, basic coding logic, and system-to-system communication.
3. Product BA (The ‘Value’ Strategist)
The Product BA merges business analysis with product management principles. Rather than just fulfilling requested requirements, they focus on why a product or feature should be built, ensuring it aligns with overarching company goals and delivers tangible ROI.
Core Focus: Product strategy, feature prioritization, market viability, and user adoption.
Day-to-day Responsibilities: Conducting market research, managing the product backlog, defining Key Performance Indicators (KPIs), and analyzing user feedback/metrics.
Key Skills: Product discovery, data analysis, competitive analysis, and strategic roadmapping.
The PMBOK Guide 8th Edition is an integrated, value-driven framework that bridges the high-level principles of the 7th edition with the practical, process-oriented structure of older editions. It reintroduces 40 non-prescriptive processes alongside six core principles and seven performance domains.
📚 The Structure: Two Books in One
Similar to its predecessors, the printed volume of the 8th Edition includes two integrated publications:
The Standard for Project Management: An official ANSI standard that focuses on strategic alignment, value delivery systems, and global applicability.
A Guide to the Project Management Body of Knowledge (PMBOK Guide): The practical handbook containing the processes, tools, techniques, and tailoring considerations.
🟢 The 6 Core Principles
The 8th Edition streamlines the 12 principles from the 7th edition into six actionable pillars designed to guide professional behavior and mindset:
Adopt a Holistic View: Think in terms of systems and understand how a project integrates with organizational strategy.
Focus on Value: Direct efforts toward long-term outcomes and net-positive benefits rather than just output production.
Build Accountable Leadership: Cultivate a culture of transparency, clear responsibilities, and high-performance teamwork.
Embed Quality: Ensure quality processes and continuous improvement are woven into every phase of the work.
Integrate Sustainability: Consider the long-term environmental, social, and economic impacts of project delivery.
Build Empowered Teams: Foster environments where team members are supported, trusted, and empowered to solve problems.
🔵 The 7 Performance Domains
These represent key areas of practice, serving as the technical “what” of your project:
Governance: Setting the rules, decision frameworks, and oversight mechanisms.
Scope: Defining boundaries, deliverables, and requirements.
Schedule: Managing timeframes, milestones, and critical paths.
Finance: Budgeting, forecasting, and cost management.
Stakeholders: Managing expectations, engagement, and communications.
Resources: Allocating people, equipment, and physical/material assets.
Risks: Identifying, analyzing, and mitigating uncertainties.
🟠 The 40 Evolved Processes & Focus Areas
A highly praised update in the 8th edition is the return of process guidance. To offer structured “how-to” guidance without becoming rigid, the processes are grouped into five Focus Areas (replacing the traditional Process Groups):
Initiating
Planning
Executing
Monitoring & Controlling
Closing
Across these five focus areas, there are 40 non-prescriptive processes that detail the typical inputs, tools, techniques, and outputs (ITTOs). The guide includes explicit tailoring advice on how to adapt these processes for predictive, hybrid, and agile environments.
💡 Key Modern Additions
Reflecting over 48,000 global practitioner data points, the 8th Edition expands coverage into modern project environments:
Artificial Intelligence (AI): Guidance on using AI and data analytics in project management.
Project Management Offices (PMOs): Expanded focus on PMO structures and strategic value alignment.
If you are planning to take the PMP exam, make sure to check the official PMI PMP Certification Overview for the most up-to-date Exam Content Outline (ECO). The exam relies heavily on the ECO, and the 8th Edition guide serves as foundational reference material.
Business Analysis (BA) from week to week, across an example project
Another example;
Business Analysis (BA) across an example project—like building a custom mobile app—follows a dynamic, week-to-week lifecycle. It shifts focus from initial high-level strategy and stakeholder alignment to granular requirements, testing support, and post-launch evaluation.
Here is how a typical BA lifecycle breaks down across an example 8-week project timeline:
Week 1: Project Kickoff & Discovery
Focus: Understanding the business problem and setting boundaries.
Activities:
Facilitating kickoff workshops with key stakeholders.
Creating a Business Case or Vision Document to define the “why.”
Identifying key project sponsors, users, and subject matter experts (SMEs).
Week 2: Stakeholder Engagement & Elicitation
Focus: Extracting needs from the people who matter.
Activities:
Conducting interviews, surveys, and Focus Groups to gather initial wants and needs.
Mapping out high-level Business Processes (current “As-Is” workflows and future “To-Be” workflows).
Week 3: Analysis & Requirements Definition
Focus: Turning raw data into structured requirements.
Activities:
Writing user stories and establishing Acceptance Criteria (often using the Given-When-Then format).
Creating documentation like process models, wireframes, and data dictionaries.
Week 4: Prioritization & Scope Management
Focus: Deciding what gets built first.
Activities:
Facilitating prioritization sessions using frameworks like the MoSCoW Method (Must have, Should have, Could have, Won’t have).
Defining the Minimum Viable Product (MVP) to prevent scope creep.
Week 5: Backlog Refinement & Solution Design
Focus: Preparing work for the development team.
Activities:
Refining the product backlog alongside the Product Owner.
Working directly with UI/UX designers and technical architects to ensure designs align with business rules.
Week 6: Development Support & Clarification
Focus: Answering daily questions and unblocking the team.
Activities:
Hosting Agile ceremonies like Sprint Planning and Daily Stand-ups.
Clarifying edge cases and adjusting requirements if technical constraints arise during development.
Week 7: Testing & Validation
Focus: Ensuring the solution works and meets business needs.
Activities:
Assisting Quality Assurance (QA) teams by explaining acceptance criteria.
Facilitating User Acceptance Testing (UAT) with real business users to sign off on the software.
Week 8: Deployment & Post-Implementation Review
Focus: Launching the product and measuring success.
Activities:
Helping prepare training materials, user manuals, and release notes.
Conducting a Retrospective to identify process improvements for the next project phase.
Centiun is a UK-based IT consultancy and Microsoft AI Cloud Partner specializing in digital transformation, Microsoft Dynamics 365, and Power Platform solutions.
Centiun is a UK-based IT consultancy and Microsoft AI Cloud Partner
Headquartered in Cheadle, Cheshire, the company delivers expert solution architecture, implementation, and managed support to public and private sector organizations.
Executive Staff & Leadership
Kieran Gerard Holmes: Director and Principal Solution Architect. A senior Microsoft expert with certifications across Dynamics 365, Power Platform, and Microsoft AI.
Wider Consulting Team: The company is built around a close-knit, highly qualified team of Microsoft Certified Professionals (MCPs) and Solutions Architects who focus on mid-market and enterprise digital change.
NHS, End User Services
Timeline Breakdown by Year
Centiun has grown rapidly in the cloud and AI solutions space. Key milestones include:
2025 (Company Foundation & Initial Certifications)
October 30, 2025: Centiun Limited was officially incorporated, establishing its registered headquarters at Cheadle Royal Business Park in Cheshire.
Late 2025: Secured nationally recognized Cyber Essentials certification and completed registration with the Information Commissioner’s Office (ICO) for secure data management compliance.
Late 2025: Began publishing specialized insight articles focused on legacy app modernization and driving intelligent, data-driven decisions via Microsoft Power BI.
2026 (Expansion & AI Solutions)
Early 2026: Positioned itself as a strategic Microsoft SME partner providing personalized digital transformations, cloud migrations, and technical governance.
Spring 2026: Expanded consulting efforts into “Agentic Customer Experience (CX)”—advising organizations on how to implement Microsoft Copilot, AI agents, and Dynamics 365 Contact Center workflows.
Spring/Summer 2026: Continued to build digital footprints across public bodies, healthcare, non-profit, and financial services sectors.
To explore how their architects can assist with your Microsoft transformations, request a consultation or view their technology resources on the Centiun website.
Centiun is a UK-based IT consultancy and Microsoft AI Cloud Partner
Agile Scrum teams use Fibonacci story points to account for exponential uncertainty, eliminate low-value debates over absolute hours, and establish relative sizing based on complexity.
Instead of using a standard linear scale (\(1, 2, 3, 4, 5…\)), Agile frameworks adopt the Fibonacci sequence (\(1, 2, 3, 5, 8, 13…\)) or a modified version (\(1, 2, 3, 5, 8, 13, 20, 40…\)) to fundamentally change how teams measure and discuss work.
🧠 The Psychology and Science of Sizing
Weber’s Law: Human brains struggle to detect minor differences in large magnitudes. While you can easily spot the difference between a 1kg and 2kg weight, you cannot easily tell the difference between 20kg and 21kg. The Fibonacci sequence mimics this by expanding the numbers proportionally (roughly a 60% jump each time), aligning with how humans naturally perceive effort.
Increasing Uncertainty: The larger a software development task is, the more unknowns it contains. The widening gaps between Fibonacci numbers (e.g., the jump from 8 to 13) visually represent this growing exponential risk and ambiguity.
Prevents False Precision: Estimating a complex feature at “39 hours” gives a false sense of security. Forcing the team to bucket a highly complex task as an 8 or 13 keeps the focus on high-level estimation rather than pixel-perfect precision.
🚀 Operational Benefits for Scrum Teams
Faster Planning Poker Sessions: Linear scales cause teams to waste valuable time arguing whether a task is a 5 or a 6. Because the Fibonacci sequence jumps straight from 5 to 8, it eliminates minor nitpicking and drives significantly quicker team alignment.
Shifts Focus to “CUE”: Story points measure Complexity, Uncertainty, and Effort altogether. Moving away from traditional hours breaks the mental link to individual time constraints, allowing a senior and a junior developer to agree on a task’s relative size even if they would complete it at different speeds.
Natural “Epic” Indicators: High Fibonacci scores serve as an immediate operational trigger. Most Scrum teams establish a rule that any user story rated an 8 or 13 is too large for a single sprint and must be broken down into smaller, bite-sized tasks.
PRINCE2 (Projects IN Controlled Environments) is a globally recognized, process-driven project management methodology. It provides a structured, scalable approach to manage projects from start to finish. It is built on 7 core principles, 7 themes, and 7 step-by-step processes.
May 2011 – Registered PRINCE2 Practitioner with ILX
The 7 Pillars of PRINCE2
To truly grasp PRINCE2, you should be familiar with its three core elements:
7 Principles: Continued business justification, learn from experience, defined roles and responsibilities, manage by stages, manage by exception, focus on products, and tailor to suit the project environment.
7 Themes: Business Case, Organization, Quality, Plans, Risk, Change, and Progress.
7 Processes: Starting Up, Directing, Initiating, Controlling a Stage, Managing Product Delivery, Managing a Stage Boundary, and Closing a Project.
Example MS Excel PRINCE2 template (available on this website)
Detailed Timeline Breakdown by Year
The evolution of PRINCE2 spans over 50 years, transitioning from an internal UK IT standard into a global, flexible methodology.
Mid-1970s: Simpact Systems Limited creates the PROMPT methodology (Project, Resource, Organization, Management, and Planning Technique).
Early 1980s: The Central Computer and Telecommunications Agency (CCTA) in the UK licenses PROMPT to manage complex IT overruns.
1989: CCTA enhances the PROMPT method, renames it to PRINCE (PROMPT in the CCTA Environment), and mandates it for UK IT projects.
1990: PRINCE is released into the public domain and experiences widespread private and public sector adoption.
1996: The UK Cabinet Office officially publishes PRINCE2 and its global certifications. The acronym is updated to PRojects IN Controlled Environments and adapted to fit any industry or project type (not just IT).
2000: Ownership transfers to the newly formed Office of Government Commerce (OGC) in the UK.
2002/2005: Manual structure undergoes major revisions to strengthen the methodology’s “product-based planning” approach.
2009: A massive “Refresh” is released. This update simplifies the framework, introduces the foundational 7 principles, and significantly improves customization.
2013: Ownership transitions to AXELOS Ltd, a joint venture between the UK Government and Capita.
2017: AXELOS publishes the PRINCE2 2017 Update (later designated the 6th Edition). This update places heavy focus on tailoring the method to project scale, flexibility, and practical execution.
2018:PRINCE2 Agile is launched, combining the traditional, controlled PRINCE2 governance model with agile delivery methods.
2021:PeopleCert, a global examination provider, acquires AXELOS and takes full ownership of the PRINCE2 methodology.
2023–Present: PeopleCert releases the PRINCE2 7th Edition, which brings modernizations, digital improvements, and greater sustainability tracking, branding the framework simply as “PRINCE2 Project Management”.
To explore the latest resources, certification paths, or officially recognized guides, you can visit the PRINCE2 Official Website or the community-driven PRINCE2 Wiki.
Scrum and Kanban are both popular Agile project management frameworks, but Scrum relies on rigid, time-boxed cycles with explicit roles, while Kanban focuses on continuous workflow and limiting work-in-progress to resolve bottlenecks.
Core Mechanics of Scrum
Time-Boxed Sprints: Work is divided into locked iterations where the team commits to a specific batch of deliverables.
Strict Ceremonies: Requires mandatory structural events including Sprint Planning, Daily Scrums, Sprint Reviews, and Retrospectives.
Clear Accountabilities: Relies on a Product Owner to dictate priorities, and a Scrum Master to eliminate work blockers.
Core Mechanics of Kanban
WIP Limits: Explicitly caps the maximum number of active items allowed in any single workflow column to prevent overloading.
Continuous Delivery: Tasks flow from the backlog to “Done” independently as resources allow, rather than in batched releases.
Evolutionary Change: Fits seamlessly over existing operational hierarchies without requiring an organizational overhaul.
How to Choose the Right Framework
Choose Scrum if:
You are building a complex product requiring highly disciplined planning cycles.
The project requires substantial stakeholder engagement and frequent product reviews.
Your team prefers structured routine, cross-functional collaboration, and highly concrete targets.
Choose Kanban if:
Your workflow is dictated by inbound, unpredictable operational tasks (like IT support or bug tracking).
You want a visual aid to reveal pipeline bottlenecks without altering current team roles.
Note: Many organizations merge these models into a hybrid approach known as Scrumban, leveraging Scrum’s regular event cadences alongside Kanban’s visual WIP flexibility.
Mark Whitfield’s Project Management Templates offer a comprehensive, fully editable toolkit of over 200 documents spanning the entire project lifecycle. Designed for PRINCE2, Agile Scrum, and Waterfall methodologies, the suite helps project managers streamline planning and tracking. The toolkit is available on platforms like Mark Whitfield’s Project Templates and Etsy – ProjectTemplatesSoft.
Here is a detailed breakdown of the templates by type:
1. Planning & Scheduling Templates
These templates help structure timelines, resource allocation, and task dependencies.
MS Project Plans (.mpp): Detailed, annotated files spanning full Software Development Life-Cycles (SDLC) and PRINCE2 7th Edition. Includes sprint overviews for Agile teams.
Excel Detailed Plans: Full Gantt chart and task tracking for users who do not have MS Project. Includes self-populating columns for baseline variance, actual effort, and RAG (Red/Amber/Green) status.
Plan on a Page (POaP): Over 30 PowerPoint slide designs that simplify complex project timelines, allowing you to present the overarching plan to clients and executives without overwhelming them with micro-details.
2. RAIDs Log Templates
These core tracking documents help manage the unknowns and variables of your project.
Basic RAIDs Log: Simple trackers for Risks, Assumptions, Issues, and Dependencies.
Comprehensive RAIDs Log: Highly detailed sheets with separate tabs to track supplier details, individual deliverables, Change Requests (CR), and out-of-scope (OOS) tasks.
3. Financial Management Templates
Designed to maintain tight control of your budget and forecast.
Monthly Finance Tracker: Simple sheets to monitor monthly forecasts, actuals, annual leave, and monthly variances.
Project Cost Tracker: Full-featured financial spreadsheets providing rate lookups, margin calculations, expense logs, and built-in charts for financial reporting.
4. Governance & Project Controls
These templates form the administrative and structural backbone, primarily based on the PRINCE2 methodology.
Project Initiation Documentation (PID): Includes templates for the Business Case, project approach, roles & responsibilities, and team structure.
Reports: Standardized documents for Checkpoint Reports, Highlight Reports, End-Stage Reports, and Exception Reports.
Logs & Registers: Tailored templates for Lessons Learned, Quality Management, and Configuration Item Records.
5. Stakeholder & Team Management Templates
Focused on communication and team alignment.
RACI Matrix: A tracker to define exactly who is Responsible, Accountable, Consulted, and Informed for each project task.
Stakeholder Analysis: Charts and planning tables designed to measure stakeholder “influence vs. impact” so you know exactly how to manage expectations.
Mobilisation Kit: Onboarding documents and team kickoff presentations to get new resources up to speed quickly.
6. Agile & Specialized Execution Templates
Agile Dependency Tracking: Tools designed specifically to monitor user stories that have hard dependencies on external suppliers or stakeholders.
Burn Down / Burn Up Charts: Visual aids in Excel to track sprint velocity and project progression against deliverables.
Benefits Realization Plan: A spreadsheet that evaluates the project’s completed deliverables against the organization’s original business goals and financial targets.
All templates are designed for use across desktop, tablet, and cloud platforms. Purchases on his site come with lifetime free upgrades for any additions he makes to the package.
Business Analyst (BA) interview prep focuses on demonstrating how you translate business problems into technical/process solutions. Preparation revolves around three core pillars: competence (technical knowledge), communication (behavioral stories), and cultural fit.
1. Technical & Core Knowledge Prep
Familiarize yourself with the fundamental BA methodologies, documentation, and tools:
Methodologies: Understand the differences between Agile (Scrum, Kanban, sprints, user stories) and Waterfall (structured phase-gating).
Documentation: Review how to create a Business Requirements Document (BRD), Functional Requirements Document (FRD), and Software Requirements Specification (SRS).
Process Modeling: Refresh your knowledge on reading and creating Use Cases, User Stories, and UML diagrams (Activity diagrams, Flowcharts).
Requirements Gathering: Be ready to discuss techniques like interviews, workshops, prototyping, and document analysis.
2. Behavioral & Scenario Prep (The STAR/STARS Method)
Expect situational questions that require you to tell a story about your past experience. Structure your answers using the STAR method (Situation, Task, Action, Result):
Conflict Resolution: How do you align stakeholders with opposing views or conflicting priorities?
Scope Creep: How do you manage a stakeholder requesting major changes midway through a project?
Ambiguity: Tell me about a time you had to work with limited data or changing requirements.
Failure/Mistakes: Describe a time you made an analytical error or missed a requirement and how you resolved it.
3. Interview Action Items Checklist
Work Samples: Bring a physical or digital portfolio containing redacted work samples (e.g., a process flow, user story backlog, or requirements document you’ve built).
The 30-60-90 Day Plan: Think about how you would approach the first few months on the job. (e.g., Day 1-30: Learn the business domain; Day 31-60: Map current processes; Day 61-90: Identify optimization opportunities.)
Reverse Questions: Prepare engaging questions to ask the interviewer, such as: “What does success look like in this role in the first 6 months?” or “Can you share more about how BAs collaborate with the technical team here?”
Agile estimation techniques use relative sizing rather than exact time tracking to gauge the effort, complexity, and risk of completing tasks. These collaborative methods help Scrum teams maintain predictable delivery and realistic workloads without relying on rigid, top-down predictions.
Common Agile estimation techniques include:
1. Planning Poker
How it works: Team members use a deck of cards with values from the modified Fibonacci sequence (0, 1, 2, 3, 5, 8, 13, 21, etc.). The Product Owner presents a user story, the team discusses it, and each member privately selects a card representing their effort estimate.
When to use it: Ideal for detailed sprint planning and backlog refinement, especially when you need to encourage team collaboration and reach a consensus.
2. T-Shirt Sizing
How it works: Tasks are assigned sizes (XS, S, M, L, XL) based on high-level complexity rather than precise points.
When to use it: Excellent for rapid, broad-brush estimation during initial release planning or when mapping out large Epics that aren’t yet refined into granular user stories.
3. Affinity Estimation
How it works: The team collaboratively groups user stories on a wall or digital board into columns representing different sizes. Every team member can move a story if they disagree with its current size, creating a consensus through comparative grouping.
When to use it: Best suited for large product backlogs where many items need to be sized quickly in a single session.
4. Dot Voting
How it works: Team members receive a limited number of physical or digital “dots” to place on user stories they believe carry the highest complexity or effort, prioritizing stories based on the concentration of votes.
When to use it: Helpful for quick prioritization and establishing a baseline for relative difficulty among a large list of tasks.
5. The Bucket System
How it works: Similar to Affinity Estimation, various “buckets” (numbered with Fibonacci sequences) are laid out. Stories are placed in the buckets, which helps the team rapidly categorize relative effort.
When to use it: Great for medium-to-large backlogs requiring faster execution than traditional Planning Poker without sacrificing sizing accuracy.
Choosing between PRINCE2 and PMP depends on your career goals and location. PMP is a global, experience-based standard highly valued in the US and multinational corporations. PRINCE2 is a process-based methodology heavily favored in the UK, Europe, and government/public sectors.
A high-level text overview highlights the following core differences:
Project Management Professional (PMP)
What it is: A globally recognized framework and body of knowledge (PMBOK) that certifies a manager’s broad project leadership skills.
Focus: People, processes, and business domains. It is highly flexible and covers predictive (waterfall), agile, and hybrid methodologies.
Requirements: Strict prerequisites. Requires 36–60 months of project management experience and 35 hours of project management education before you can take the 180-question exam.
Best for: Experienced project managers seeking global mobility and opportunities in corporate and private sectors.
What it is: A structured, prescriptive methodology that gives you a step-by-step guide on how to run a project from start to finish.
Focus: Governance, defined roles, continuous business justification, and documentation. It uses a scaleable “Tailoring Approach” so it can be adapted to projects of varying sizes.
Requirements: No mandatory experience needed for the Foundation level, making it accessible to beginners. The Practitioner level tests your ability to apply the framework.
Best for: Early-to-mid career professionals and those targeting government, NHS, or public sector roles within the UK and Europe.
Official Hub: Browse certification pathways via Axelos.
You can review or download the targeted, one-page CV for Mark Whitfield (Senior Project Manager specializing in HPE NonStop systems) via the Mark Whitfield CV PDF link.
Mark Whitfield, High-Level Project Management Summary
The high-level, scannable overview of his professional profile is outlined below:
Executive Profile
Role: IT Senior Project Manager / Delivery Lead
Background:30+ years of experience delivering highly complex technology, business transformation, and infrastructure projects.
Core Skills: Cloud migration (hybrid), legacy ATM software modernisation, Point of Sale (POS) implementations, and software development lifecycles (SDLC).
Methodologies: Agile, Waterfall, PRINCE2 Practitioner, and ITIL certified.
Core Expertise & Competencies
HP NonStop & Legacy Integration: Deep technical roots in Tandem Computers/ HPE NonStop development, TAL programming, and high-volume transaction environments.
Global Delivery: Managed large-scale IT and system monitoring rollouts across the UK and international markets (e.g., Saudi Arabia).
Stakeholder Management: Experienced in bridging the gap between highly technical development teams and high-level business stakeholders.
For direct access to his official templates, articles, and full professional journey, you can visit the PROject Templates Website.
Microsoft Power Platform is an enterprise-grade, low-code platform that allows organizations to build applications, automate workflows, analyze data, and create AI-powered virtual agents. It natively connects to Microsoft 365, Azure, and Dynamics 365, serving as a core pillar of modern digital transformation.
Microsoft Power Platform Overview
Core Pillars
Power Apps: A low-code development environment for building custom, cross-platform business applications (Canvas or Model-driven) without writing traditional code.
Power Automate: An automation service enabling the creation of workflows, API-based integrations, and Robotic Process Automation (RPA) for legacy systems.
Power BI: A business analytics service that provides interactive visualizations and business intelligence capabilities with an interface simple enough for end users to create their own reports and dashboards.
Power Pages: A secure, enterprise-grade low-code software-as-a-service (SaaS) platform for designing, configuring, and publishing external-facing websites.
Microsoft Copilot: AI-assisted generative capabilities natively built across the platform, allowing users to build apps, write flows, or generate reports using natural language.
Foundational Technologies
Dataverse: A secure, cloud-based data storage and management layer featuring a standardized common data model, allowing disparate Microsoft tools to seamlessly share information.
Connectors: Over 1,000 pre-built wrappers that facilitate communication between the Power Platform and external services (like Salesforce, SQL databases, or REST APIs).
Power Fx: A low-code, strongly-typed functional programming language based on Excel formulas that serves as the logic layer across the platform.
Technical Evolution by Year
The Power Platform did not launch overnight; it evolved through the gradual introduction of several standalone tools before Microsoft formally unified them under one umbrella.
2013–2015: The Origins of Data Analysis & Logic
2013: Power BI is initially released as an add-in for Microsoft Excel, allowing users to build pivot tables and light analytics.
2015: Power BI transitions into a standalone cloud service. Concurrently, Power Apps enters public preview, introducing the low-code app paradigm.
2016–2017: Workflow Automation
2016: Microsoft Flow (the predecessor to Power Automate) is launched to handle cloud-based workflow automation.
2017: Common Data Service (now Dataverse) is introduced to provide a standardized, secure data layer.
2018–2019: The “Power Platform” Unification
2018: Microsoft officially unifies Power BI, Power Apps, and Microsoft Flow under the official name “Microsoft Power Platform”, introducing the formal concept of a connected, low-code business ecosystem.
2019: The Common Data Service gets deeper integration across Dynamics 365 and Microsoft 365, accelerating citizen development across large enterprises.
2020: AI and Robotic Process Automation (RPA)
2020: Microsoft launches AI Builder, allowing users to integrate pre-trained AI models (like form processing and object detection) directly into their apps and workflows.
2020: Softomotive is acquired, bringing RPA (desktop flows) into Power Automate.
2021–2022: New Additions and Expanded Web Presence
2021: The Common Data Service is officially rebranded as Microsoft Dataverse.
2021: Power Fx is introduced as the standard, open-source low-code language.
2022: Power Apps Portals is rebranded and expanded into Power Pages, creating a dedicated, robust tool for building external-facing websites.
2023–2024: The Generative AI Wave
2023: Microsoft embeds generative AI across the suite through Copilot. Users begin building data tables, applications, and automation flows entirely through conversational prompts.
2024: Power Platform deepens its integration with Microsoft Fabric and brings further enterprise-grade management, data governance, and AI agent orchestration features directly into Dataverse.
2025–2026: Agentic Computing and Modern Controls
2025: Power Platform evolves beyond standard applications and automations into “agentic computing.” Makers can build autonomous, AI-driven data agents directly within Dataverse using the Python SDK.
2026: Power Apps rolls out massive updates to its interface, deploying responsive layouts and modern controls as default settings. Advanced lifecycle management and process-mining features cement the platform’s role in modern fusion development.
My Recent MS Power Platform Involvement :
UK Gov : Cloud Migration (Hybrid) – In 2020, working as a Senior Project Manager on a client sponsored Agile proof-of-concept (POC) project to move 3 Client elected Apps (with MS Access, Oracle and SQL 2008 DBs), to the Cloud (Microsoft Azure and Dynamics365 Power Platform). The migration to the cloud was based on 3 primary app patterns namely; re-host, re-platform and re-factor. This project spanned approximately 3 months and started in early February 2020 with a budget of £375k.
The project was a pre-cursor and effort indicator for the larger piece of migration work to move 130 client estate apps to the cloud. This is a very complex app estate with many touch points and different technology stacks.
As the Capgemini Senior PM, responsible for the project planning, control, organisation, stakeholder communication, aligning with current GDPR directives and status reporting against delivery of Capgemini services to the client. As the PM, also the first escalation point for the project team and the client.
December 2022 – C&CA UK’s Communications & Engagement Award Winner – Cloud & Custom Applications – Capgemini UK
Project Management Office (PMO) models dictate the structure, control level, and strategic focus of a PMO within an organization. The most common frameworks break down into three primary operational types, alongside broader structural and strategic classifications that define how governance is applied.
Project Management Office (PMO) models overview
1. Operational Models (By Control Level)
These models define how the PMO interacts with project teams and enforces standards.
Supportive PMO: Acts as an advisory entity. It provides templates, best practices, training, and tools on demand, but has no direct control or authority over project execution. Best for: Organizations with a decentralized, highly autonomous culture.
Controlling PMO: Enforces strict governance, standardizes methodologies, and ensures compliance across all initiatives. It provides more than advice and actively verifies adherence, but typically relies on established escalation paths rather than direct authority. Best for: Organizations that need consistency and reduced risk.
Directive PMO: Assumes full control and direct ownership of projects. The PMO assigns project managers, directs resources, and takes total responsibility for execution, timelines, and outcomes. Best for: Complex or mission-critical projects requiring rigid governance.
2. Structural Models (By Scope & Placement)
These classifications indicate where the PMO sits and its organizational reach.
Enterprise PMO (EPMO): Operates at the highest organizational level, overseeing the entire project portfolio. It ensures all programs directly align with overarching corporate business objectives and strategy.
Departmental/Divisional PMO: Supports specific business units (such as IT, Marketing, or Engineering). It is highly tailored to the specialized needs of that function, though it runs the risk of creating siloed practices.
Embedded or Project-Specific PMO: A temporary model dedicated to one large, highly complex, or mission-critical project or program. It lasts for the duration of the project and then disbands or reallocates.
3. Advanced / Strategic Models (By Focus)
Modern organizations often adapt the PMO to focus on high-level value rather than just tracking timelines.
Center of Excellence (CoE): Focuses heavily on continuously elevating the organization’s project management maturity. It acts as an innovation hub for methodologies, technology evaluation, and skill-building.
Value Management Office (VMO): Focuses entirely on benefits realization and return on investment (ROI). Rather than just asking “are we on time?”, it asks “is this project generating the business value we wanted?”
A Project Management Office (PMO) is a centralized department within an organization tasked with standardizing project management processes, enforcing governance, and aligning projects with strategic business goals. Its primary mission is to optimize resource utilization, mitigate risks across the portfolio, and improve the overall success rate of projects.
The core responsibilities of a PMO vary based on its organizational maturity and type (Supportive, Controlling, or Directive), but generally span five major domains:
1. Governance and Standardisation
Developing Methodologies: Establishing uniform frameworks, processes, and project management methodologies (such as Agile, Waterfall, or hybrid models) across all departments.
Creating Templates: Developing standard documentation, templates, and tools to ensure consistency in project initiation, tracking, and reporting.
Conducting Audits: Monitoring compliance with established standards through health checks and project reviews to identify and correct process deviations.
2. Strategic Portfolio Management
Strategic Alignment: Ensuring every project investment directly supports the organization’s high-level strategy and long-term business goals.
Project Prioritization: Evaluating incoming project proposals and business cases to prioritize high-value initiatives while deferring or canceling low-priority options.
Benefits Realization: Tracking and measuring project outcomes to ensure that completed deliverables provide the expected economic or structural value to the company.
3. Monitoring, Tracking, and Reporting
Performance Reporting: Collecting and analyzing performance metrics via dashboards to provide regular progress updates to senior executives and stakeholders.
Dependency Management: Tracking cross-project dependencies, scheduling overlaps, and potential bottlenecks to prevent organizational conflicts.
Risk Management: Identifying systemic risks and early-warning signs of failing projects to trigger timely interventions or escalation protocols.
4. Resource and Capacity Management
Resource Optimization: Coordinating the allocation and utilization of personnel, skill sets, and budgets across the entire project portfolio.
Capacity Planning: Assisting line managers with strategic capacity planning to identify talent gaps, prevent team burnout, and support hiring decisions.
Effort Estimation Support: Providing historical data and expert insights to help project teams produce accurate cost and time estimates.
5. Training and Knowledge Management
Mentorship and Coaching: Providing regular guidance, professional coaching, and continuous support to project managers and their delivery teams.
Skills Development: Organizing training sessions and educational paths on core project management practices, specialized software, and new industry standards.
Lessons Learned Repository: Maintaining a centralized repository of project documentation, historical metrics, and post-project reviews to drive continuous organizational learning.
Scrum velocity and burndown charts are essential agile metrics used to measure team capacity and track progress. Velocity measures the average story points completed over past sprints to forecast future capacity. Burndown charts visually represent the remaining work daily, highlighting if the team is on track to meet sprint goals.
Scrum Velocity
Definition: The amount of work (usually in story points or hours) a team completes in a single sprint.
Purpose: Helps forecast team capacity for future sprints and promotes sustainable pace.
Calculation: Sum of story points for all “Done” items at the end of a sprint.
Best Practice: Average velocity over 3–5 sprints provides a more accurate, stable forecast.
Burndown Chart
Definition: A graph showing the amount of work remaining versus time (days) in a sprint.
Components:
Ideal Work Line: A straight line showing the projected pace to complete work.
Actual Work Line: A line plotting daily completed work against the ideal line.
Purpose: Provides daily visibility into progress and detects risks early (e.g., if the line is above the ideal, the team is behind).
Types: Sprint Burndown (short term) vs. Release/Product Burndown (long term).
Key Differences
Velocity is a planning metric looking at historical performance.
Burndown is a monitoring tool looking at current progress.
Common Pitfalls
Velocity: Treating velocity as a productivity metric (it is a capacity planning metric) or comparing it between teams.
Burndown: Using “manual updates” rather than automated tools, leading to inaccurate data.
Both: Neglecting to refine user stories, which makes velocity unpredictable and burndowns inaccurate.
Business analyst deliverables are essential documentation and artifacts produced throughout a project to define business needs, bridge gaps between stakeholders and technical teams, and ensure solutions deliver value. Key deliverables include the Business Case, Stakeholder List, Requirement Packages (BRD/User Stories), Process Models, and Transition Requirements.
Core Business Analyst Deliverables by Phase:
Initiation/Discovery:
Business Case: Outlines the justification for the project, including cost-benefit analysis and ROI.
Problem Statement/Project Scope: Defines the “why” and boundaries of the project.
Stakeholder Map/Matrix: Identifies key stakeholders and their influence.
Planning:
Business Analysis Plan: Outlines the approach, tasks, and techniques to be used.
Communication Plan: Defines how stakeholders will receive updates.
Elicitation & Analysis:
Current State Assessment (As-Is): Documents how processes work today.
Future State Modeling (To-Be): Visualizes the desired future processes.
Gap Analysis: Details what needs to change to get from current to future state.
Business Requirements Document (BRD): A formal document detailing what the business needs to achieve.
Solution Definition (Design & Implementation):
Functional/Non-Functional Requirements (SRS): Technical details on how the system should act.
Use Cases/User Stories: Detailed scenarios of user interactions with the system.
Prototypes/Wireframes: Visual representations of user interfaces.
Product Backlog (Agile): A prioritized list of user stories.
Evaluation & Closure:
Acceptance Criteria & Test Cases: Defines the criteria for a completed feature.
Solution Assessment/Validation Report: Evaluates if the delivered solution met the needs.
Lessons Learned/Closing Report: Documents successes and improvements for future projects.
Key Takeaways:
Formal vs. Informal: Plan-driven (Waterfall) projects use heavy formal documentation (BRD, SRS), while change-driven (Agile) projects focus on lighter tools like user stories, Jira tickets, and prototypes.
Value-Driven: Deliverables exist to facilitate communication, align stakeholders, and ensure project success.
Note: The specific deliverables required are usually determined in the initial project planning stage.
Mark Whitfield, a Manchester-based Senior IT Project Manager, has completed extensive professional training throughout his career, focusing on project management methodologies, delivery software, and technical tools.
Core Project Management Methodologies :
PRINCE2 Practitioner: Certified as a registered PRINCE2 Practitioner in May 2011 via the ILX Group (Gold e-Learning).
Agile SCRUM Training: Attended in-house training with RADTAC in May 2011.
Advanced Engagement Management (Level 2): Completed at Capgemini in November 2017.
Project Management Fundamentals: Completed “Fundamentals of Successful Project Management” in February 2000 through Skillpath in Manchester.
Managing Multiple Projects: Attended “Managing Multiple Projects, Objectives and Deadlines” in October 1999/1998 via Skillpath.
Software & Cloud Platforms :
AZ-900 Microsoft Azure Fundamentals: Certified in February 2022.
Microsoft Project: Completed the Microsoft Project ’98 Certification Series in May 2000 through the IIL UK Education Centre in Reading.
Microsoft Excel Expert Skills: Upgraded skills via a 2017 Expert course and a July 2024 Udemy refresher.
Technical & Programming Courses :
Tandem / HP NonStop: Completed Tandem Guardian Principles (1993), Tandem Performance Analysis (1995), and Tandem TAL Programming (1995).
C / C++ Programming: Attended “C++ for Non-C Programmers” with Comtec Computer Training in March 1997.
Database Querying: Completed “Querying Microsoft SQL 2000 with Transact SQL” via QA Training in March 2009.
Web Applications: Attended “Developing MS ASP Web Applications using MS Visual Studio .NET” in January 2007.
Marketing & Communication Training :
Writing for the Web: Completed in May 2009 with gbdirect (iTrain Education in London).
Brochure & Document Design: Attended a SkillPath Seminar on designing marketing brochures and reports in April 2006.
A RAID log is a central project management tool used to track Risks, Assumptions, Issues, and Dependencies to ensure project success and stakeholder alignment. It is essential for complex projects, updated regularly to manage, monitor, and mitigate factors that could affect deliverables, typically maintained as a living spreadsheet or document.
Key Components of a RAID Log
Risks: Potential future problems identified and mitigated before they occur (e.g., “supplier may delay shipment”).
Actions: Specific tasks, action items, or decisions that need to be addressed, often used in agile projects.
Issues: Known, current problems that have already occurred and require immediate resolution.
Dependencies: Internal or external relationships that, if not managed, can cause delays, such as waiting on another team.
Benefits of Using a RAID Log
Proactive Planning: Allows teams to identify and prepare for potential issues early.
Centralized Information: Provides a single, updated document for tracking, improving communication with stakeholders.
Improved Decision-Making: Helps in making informed decisions by logging the impact of changes.
Audit Trail: Acts as a record for project meetings, reviews, and post-mortem analysis.
How to Implement a RAID Log
Start Early: Create the log during the project planning or initiation phase.
Update Frequently: Review and update the log consistently, at least after every team meeting or weekly.
Assign Owners: Ensure every risk and issue has a specific person responsible for it.
Use a Template: Use an Excel or project management software tool, tracking columns like description, owner, impact, and status.
While some teams use it primarily for risks and issues, the “A” and “D” can stand for Actions and Decisions, respectively, depending on the team’s needs.
Mark Whitfield is a highly experienced Senior IT Project Manager based in Manchester, UK, with over 31 years of experience in the IT industry specializing in both Agile and Waterfall methodologies. He holds SC clearance (valid until 2031) and has a strong technical background in banking and digital project delivery, including experience as a developer in software development lifecycles (SDLC).
Mark Whitfield is a highly experienced Senior IT Project Manager based in Manchester
Professional Biography
After graduating in Computing in 1990, Mark began his career as a programmer specializing in Electronic Banking software on Tandem Mainframe Computers (HPE NonStop). He spent five years coding in COBOL85 and NonStop SQL for banking clients before transitioning into project management.
Mark has operated as a Senior IT Project Manager for over two decades, delivering complex projects for major blue-chip clients, including Jaguar Landrover, Heathrow, Royal Mail Group, and various financial institutions. He currently provides project management templates based on his extensive experience via his website, PROject Templates.
Example POaP Plan On a Page templates by Mark Whitfield
Projects: Delivered Waterfall and Agile digital projects for automotive, local regional government (LRG), postal services, and aerospace & defence sectors.
C&CA UK’s Communications & Engagement Award Winner 2022
Betfred (Late 2014 – Jan 2016)
Role: Senior IT Project Manager.
Projects: Managed mobile and online gambling/casino projects, including payment gateways, sportsbook, and virtual gaming using Agile SCRUM.
Wincor Nixdorf (Sept 2013 – Late 2014)
Role: Agile IT PM, Professional Services – Banking Division.
Projects: Managed ATM software delivery (Wincor Nixdorf work stream >£5M) for Lloyds Banking Group/Halifax.
Mark Whitfield provides a variety of Plan On a Page (POaP) templates designed to simplify complex project schedules into a single, high-level visual. These templates are typically available through his official website as part of a larger project management toolkit that includes over 200 editable documents.
PowerPoint Plan On a Page (POaP) templates
Mark Whitfield’s POaP Template Formats
Whitfield’s templates are available across multiple platforms to suit different project needs:
PowerPoint POaP Templates
Includes over 35+ slide examples showing different ways to visualise a Software Development Life Cycle (SDLC) plan. These are ideal for client presentations where high-level detail is needed.
Excel POaP & Tracker Templates
Features Gantt views, resource costing grids, and Agile Sprint views. Some Excel versions allow you to align the POaP with resource availability and overall phase costs, useful for project bids.
MS Project (MPP) Templates
Detailed PRINCE2 and Waterfall templates that can be condensed into a “timeline” view to serve as a POaP. These are annotated for tasks like Agile Scrum ceremonies or specific PRINCE2 7th Edition stages.
Key Features of the POaP Templates
Adaptability: Templates are designed to be tailored for Waterfall (PRINCE2) or Agile (Scrum/Sprints) methodologies.
Integrated Tracking: Often bundled with RAID logs (Risk, Action, Issue, Dependency) and RACI trackers to provide a complete overview beyond just the schedule.
Visual Dashboards: Many versions include self-populating charts and summary dashboards for at-a-glance status reporting.
Availability: Templates can be purchased individually or as a bulk pack on Mark Whitfield’s Website or through platforms like Etsy and Eloquens.
A Service Delivery Manager (SDM) acts as the primary liaison between an organization and its clients, ensuring services are delivered efficiently, meeting contractual obligations (SLAs), and maintaining high client satisfaction. They oversee daily operations, manage client relationships, and drive continuous service improvements.
Key Responsibilities and Duties:
Client Relationship Management: Acting as the central point of contact for service-related issues, leading service review meetings, and ensuring client satisfaction.
SLA & Performance Monitoring: Monitoring key performance indicators (KPIs) and Service Level Agreements (SLAs) to ensure compliance with contractual obligations.
Operational Excellence: Implementing best practices, identifying areas for improvement, and managing continuous service improvement plans.
Incident Management: Managing escalated service issues, leading root cause analysis (RCA), and ensuring swift resolution to restore service.
Team Leadership: Providing guidance, mentoring, and support to technical or support teams to meet performance goals.
Financial Management: Overseeing budgets, managing service credits, and identifying opportunities for cost savings or added value.
Required Skills and Qualifications:
Experience: Proven track record in service delivery, customer success, or project management.
Framework Knowledge: Strong understanding of ITIL frameworks is often required.
Communication: Excellent verbal and written communication skills for building rapport with clients and stakeholders.
Analytical Thinking: Ability to analyze service performance data and make data-driven decisions.
Leadership: Strong leadership skills to drive improvements and resolve conflict.
Common Industries:
Information Technology (IT) & Managed Service Providers (MSPs)
A Project Management Office (PMO) is a centralized department or group that defines, maintains, and ensures project management standards across an organization. It serves as the “command center” that aligns project execution with broader business strategy to improve success rates and ROI.
Core PMO Models
The level of control a PMO exerts depends on its specific operational model:
Supportive PMO: Provides a consultative role by supplying templates, best practices, and training. It has low control, acting primarily as a project repository.
Controlling PMO: Enforces governance and requires compliance through specific frameworks and tools. It maintains a moderate degree of control.
Directive PMO: Directly manages projects by assigning project managers who report to the PMO. This model offers the highest degree of control and accountability.
Key Responsibilities
A PMO’s daily functions bridge the gap between high-level strategy and ground-level execution:
Common PMO Roles:
Common PMO Roles
Staffing varies by organization size, but typical roles include:
PMO Director/Manager: Oversees the entire office, ensuring processes are followed and goals are met.
PMO Analyst: Collects and analyzes project data to support decision-making and reporting.
Project/Portfolio Managers: Lead individual projects or entire portfolios to completion.
PMO Specialist: Focuses on implementing methodologies and providing expert advice on project management.
Organizational Levels
PMOs can operate at different tiers within a company:
Project PMO: Focused on a single, large-scale project.
Program/Department PMO: Oversees a group of related projects within a specific department (e.g., IT or Marketing).
Enterprise PMO (EPMO): Operates at the executive level, ensuring all projects across the entire organization align with strategic corporate goals.
Business Analysts and Artificial Intelligence AI, future
Artificial Intelligence (AI) is fundamentally shifting the role of the Business Analyst (BA) from a focus on routine data processing and documentation to more strategic, human-centric activities. While AI excels at identifying patterns and automating labor-intensive tasks, it currently lacks the contextual awareness and emotional intelligence required to manage complex stakeholder relationships.
Core AI Applications for Business Analysts
AI functions as a high-speed “copilot” that streamlines the traditional BA lifecycle.
Requirement Generation: AI can process meeting transcripts to draft an initial list of requirements, user stories, or a Business Requirements Document (BRD).
Data Analysis & Forecasting: Machine learning algorithms can identify subtle trends in large datasets and move analysis from descriptive (what happened) to predictive (what might happen).
Visual Modeling: Tools can now generate process flows, data models, and architecture diagrams from simple text descriptions, drastically reducing time spent on manual formatting.
Information Elicitation: Analysts can use AI to quickly extract key details from vast document repositories or prepare for stakeholder interviews by anticipating potential questions.
Skills That Remain Uniquely Human
As AI handles the “grunt work,” the most valuable BA skills are those that cannot be easily automated.
Strategic Thinking: Connecting big-picture organizational goals to specific technical solutions and defining the “why” behind an initiative.
Stakeholder Management: Navigating office politics, facilitating discussions to resolve disagreements, and building trust across teams.
Creative Problem Solving: Tackling ambiguous business challenges where there is no clear historical data for an AI to learn from.
Critical Evaluation: Fact-checking AI outputs to ensure they are accurate and free from “hallucinations” before they influence business decisions.
The Shift from “AI4BA” to “BA4AI”
A new perspective emerging in the field is that BAs shouldn’t just use AI, but should lead the organization’s AI adoption.
Guiding Implementation: BAs act as strategic enablers, ensuring that AI projects solve meaningful problems rather than just chasing technological trends.
Managing Risk: Analysts play a critical role in addressing ethical concerns, bias detection, and security risks associated with AI-driven systems.
Bridging the Gap: They serve as the essential link between technical AI teams and non-technical business leaders to ensure projects deliver tangible value.
Future Career Outlook
The consensus among industry experts is that AI will transform—rather than eliminate—the BA profession. The market for business analytics is projected to grow significantly through 2031. Analysts who successfully integrate AI into their workflow to enhance productivity are expected to replace those who do not.
PRINCE2 Agile combines the structured governance of PRINCE2 with the flexibility of agile methods (like Scrum and Kanban) to manage projects effectively. It focuses on maintaining control, transparency, and high-quality delivery while empowering teams, making it ideal for fast-paced environments.
Key Aspects of PRINCE2 Agile:
Structure + Flexibility: It provides the framework to guide projects, while allowing the use of agile techniques to build the product.
Key Focus Areas:
The Agilometer: Assesses the level of risk and agility in a project.
Requirements: Prioritized to ensure the most valuable features are delivered first.
Rich Communication: Emphasizes face-to-face interaction and team rooms.
Frequent Releases: Ensures regular delivery and feedback loops.
Tailored Governance: Allows projects to remain aligned with organizational goals while keeping the flexibility needed for innovation.
Compatibility: Works well with various agile methods including Scrum, Kanban, and Lean Startup.
Main Benefits:
Increased Flexibility: Enables faster adaptation to changes and new information.
Improved Quality: Focuses on delivering high-quality products that meet client needs.
Enhanced Control: Provides necessary governance for project success.
When to Use:
Projects requiring both structure and high responsiveness.
Teams using Agile techniques who need to satisfy governing bodies.
Situations demanding regular, iterative delivery of results.
PRINCE2 (PRojects IN Controlled Environments) is a structured, process-driven project management method used internationally to deliver projects within time, cost, and quality constraints. Originally developed for IT projects, it has evolved into a generic, flexible, and scalable framework applicable to any type of project, now owned by PeopleCert.
Detailed Overview of PRINCE2 (2026 Framework)
As of 2026, the current framework is PRINCE2 7th Edition, launched in late 2023. It is characterized by its focus on people, digital tools, and sustainability, while retaining its core focus on governance.
MS Project MPP template example
1. The Seven Principles (Why PRINCE2 is used)
Continued Business Justification: A project must have a valid business case.
Learn from Experience: Lessons are documented and used.
Defined Roles and Responsibilities: Clear organizational structure.
Manage by Stages: Projects are broken into manageable chunks.
Manage by Exception: Empowerment given to managers to act within tolerances.
Focus on Products: Focus on deliverables rather than activities.
Tailor to Suit the Project: Adapted to suit the project’s size, environment, and complexity.
2. The Seven Themes (What must be managed)
Business Case
Organization
Quality
Plans
Risk
Change
Progress
3. The Seven Processes (How to manage)
Starting up a Project
Directing a Project
Initiating a Project
Controlling a Stage
Managing Product Delivery
Managing a Stage Boundary
Closing a Project
4. Certification Levels
Foundation: Confirms basic knowledge of the methodology.
Practitioner: Tests the ability to apply and tailor the method to scenarios.
Detailed Timeline Evolution by Era and Year
PRINCE2 has evolved from a niche IT methodology to a global standard through three major revisions.
Era 1: The Foundations (1975–1989)
1975: Simpact Systems Ltd. creates the PROMPT (Project, Resource, Organization, Management, and Planning Technique) methodology.
Early 1980s: UK Central Computer and Telecommunications Agency (CCTA) licenses PROMPT.
1989: CCTA enhances PROMPT II, renaming it PRINCE (PROMPT in the CCTA Environment), mandated for UK IT projects.
Era 2: Launch and Public Adoption (1990–2005)
1990: PRINCE is released into the public domain.
1996:PRINCE2 is released by CCTA, designed for a broader range of projects (non-IT).
2000: Ownership transfers to the UK Office of Government Commerce (OGC).
2002/2005: Major revisions to the manual structure, strengthening the “product-based planning” approach.
Era 3: Modernization & Privatization (2009–2021)
2009: Major “Refresh” released, introducing the seven principles, themes, and processes. Focuses on simplicity and customizability.
2013: Ownership transfers to AXELOS Ltd, a joint venture between the UK Government and Capita.
2017:PRINCE2 2017 Update (6th Edition) is released, focusing on enhanced flexibility and tailoring guidance.
BRD vs FRD, Business Requirements vs Functional Requirements
The primary difference between a Business Requirement Document (BRD) and a Functional Requirement Document (FRD) is that the BRD focuses on “why” a project is needed (business objectives), while the FRD details “how” the system will work to meet those needs. The BRD serves stakeholders and leadership, whereas the FRD guides developers and technical teams.
Key Differences at a Glance:
BRD (Business Requirements Document):
Goal: Defines business objectives, goals, and high-level needs.
Key Content: Business problem, scope, ROI, high-level project goals.
FRD (Functional Requirements Document):
Goal: Translates business needs into detailed technical functionalities.
Focus: “How” the system will perform to meet requirements.
Audience: Developers, Testers, Technical Team, Business Analysts.
Key Content: Feature descriptions, user interactions, system workflows, data requirements, UI mockups.
How They Work Together: The BRD is created first to get approval for the project, while the FRD is developed based on the approved BRD. The FRD ensures the project is actionable, testable, and feasible. In Agile, these are often combined into smaller artifacts like User Stories.
Mark Whitfield is a highly experienced, SC-cleared Senior Project Manager and IT professional with over 31 years of experience in both public and private sectors, specializing in software development, cloud migration, and IT systems delivery.
He is currently associated with Capgemini (since 2016) and runs a project management resource website, PROject Templates.
Joined Capgemini in 2016 having worked at ascending points in software development lifecycle projects for over 31 years
Key Qualifications & Experience:
Roles: Senior Project Manager, Engagement Project Manager, Delivery Manager, and former programmer.
Methodologies: PRINCE2 Practitioner, skilled in both Waterfall and Agile (SCRUM) approaches.
Sector Experience: Extensive experience in finance and banking, including ATM software swap-outs, cloud migration (Azure, AWS, Power Platform), and POS monitoring systems.
Background: Graduated in Computing in 1990; worked as a developer (COBOL, SQL, Tandem / HPE NonStop) before transitioning to project management.
PRINCE2 Practitioner, skilled in both Waterfall and Agile (SCRUM) approaches
Professional Highlights:
Delivered major projects for clients such as Barclays, Bank of England, HSBC, Royal Mail Group, UK & Welsh Government, Heathrow, and Jaguar Land Rover.
Led complex IT infrastructure projects and business transformations.
Maintains mark-whitfield.com, offering over 200 project management templates, trackers (RAID, budget, benefit, cost etc.), and many plans for Agile / Waterfall projects including 30+ Plan On a Page (POaP) and MS Project MPP examples (click on Blog above for a summary).
Provides specialized templates for PRINCE2 7th edition and MS Project (MPP).
December 2022 – C&CA UK’s Communications & Engagement Award Winner – Cloud & Custom Applications – Capgemini UKNovember 2017 – Advanced Engagement Management Course – Level 2 ExamJune 1990 – Higher National Diploma in Computer Studies, Distinction
As of 2026, AI is transforming project management by automating scheduling, risk management, and reporting. The best AI courses for project managers (PMs) focus on practical application, generative AI, and AI governance.
Top AI Courses and Certifications for Project Managers
PMI Certified Professional in Managing AI (PMI-CPMAI) (PMI)
Summary: The premier certification for managing AI projects from start to finish, including data prep and model deployment.
Best For: Advanced specialists managing AI projects.
Prioritization in AgileScrum is the systematic process of ordering Product Backlog items to maximize value delivery. These techniques are generally categorized by their primary focus: customer satisfaction, business value and economics, or collaborative consensus.
Category 1: Customer-Centric Frameworks
These methods prioritize features based on how they impact the end-user’s experience and satisfaction.
Kano Model: Categorizes features into three main types: Basic Needs (expected essentials), Performance Features (linear satisfaction), and Excitement Needs (unexpected “delighters”).
User Story Mapping: Visualizes the entire user journey to identify the most critical paths and “skeletal” features needed for a Minimum Viable Product (MVP).
Opportunity Scoring: Uses customer research to find gaps where importance is high but current satisfaction is low, identifying high-potential opportunities.
Category 2: Economic & Quantitative Models
These data-driven techniques use formulas to balance value against implementation costs or risks.
Weighted Shortest Job First (WSJF): Prioritizes tasks by dividing the Cost of Delay (value, urgency, and risk reduction) by Job Size (effort). The goal is to deliver the most value in the shortest time.
RICE Scoring: Calculates a score based on Reach (number of users), Impact, Confidence (certainty in estimates), and Effort.
Cost of Delay (CoD): Measures the economic impact or potential revenue loss of not delivering a feature within a specific timeframe.
Category 3: Stakeholder & Team-Based Consensus
These collaborative methods are used to reach agreement among diverse stakeholders or team members.
MoSCoW Method: A qualitative technique that buckets items into Must-Have, Should-Have, Could-Have, and Won’t-Have for a specific release cycle.
100-Dollar Test: Participants are given a hypothetical $100 to “spend” on features, revealing what they value most through resource allocation.
Priority Poker: A gamified, collaborative approach where team members anonymously vote on an item’s priority level to remove bias and foster discussion.
Category 4: Structural & Visual Matrixes
These tools help teams visualize trade-offs, typically using 2×2 grids.
Value vs. Effort Matrix: Plots tasks on two axes to identify Quick Wins (high value, low effort) and Major Projects (high value, high effort) while avoiding “thankless tasks”.
Risk/Value Matrix: Balances potential business rewards against technical or project risks to decide which high-value but high-risk items to tackle early.
Stack Ranking: A “forced ranking” method where every item has a unique, linear position (1 to N), preventing the “everything is high priority” trap.
Before launching any project, answering key questions during the initiation phase ensures alignment, prevents scope creep, and sets the foundation for success. These questions help define the “why,” “what,” and “how” of the project, often formalized in a project charter or statement of work (SOW).
Overview: The 5 Ws of Pre-Kickoff
The most effective pre-kickoff approach centers on the 5 Ws + H:
Why: What is the business purpose, problem to solve, or opportunity?
What: What are the high-level objectives, scope, and deliverables?
Who: Who are the stakeholders, sponsors, and team members?
When: What are the milestones, hard deadlines, and time constraints?
Where: Where will work take place (e.g., remote, onsite, systems used)?
How: How will success be measured and how will communication work?
Detailed Description of Essential Pre-Kickoff Questions
1. Context & Rationale (“Why”)
What is the core problem or opportunity? Define the “pain point” triggering this project.
How does this align with company strategy? Understand why this project matters now compared to other priorities.
What happens if we fail or do nothing? This identifies the true urgency.
2. Objectives & Success Criteria (“What”)
What are the measurable goals? Define success (e.g., specific KPIs, revenue increase, time reduction) rather than just stating “improved efficiency”.
What is explicitly in-scope? List the key deliverables.
What is out of scope? Crucial for preventing scope creep—list items that won’t be delivered.
What is the “Minimum Viable Product” (MVP)? What is the absolute bare minimum needed to launch?
3. Stakeholders & Roles (“Who”)
Who is the Project Sponsor? Who is championing the project and ultimately accountable?
Who has final sign-off authority? Identify the key decision-makers to avoid bottlenecks.
Who is the target audience/end-user? Who is this being built for?
Do we have the right skills on the team? Assess the need for external resources or specialized training.
4. Constraints & Logistics (“When” & “Where”)
Is the deadline fixed or flexible? Are there immovable external dates (e.g., conferences, legal compliance)?
What is the rough budget? Have all funds been secured?
What are the key milestones? Identify early dependencies.
5. Risks & Dependencies
What are the major threats? Identify risks to the schedule, budget, or quality early.
What dependencies exist? What outside factors (e.g., vendor delivery, legal approval) must happen first?
6. Operating Model (“How”)
How will the team communicate? Define tools (e.g., Slack, email) and meeting cadence (e.g., weekly, daily standups).
How will we track progress? Where will documentation and tasks be stored (e.g., Jira, Asana)?
Summary Checklist for Pre-Kickoff Success
Business Case Approved: Does a charter exist?
Goals Aligned: Do stakeholders agree on what success looks like?
Constraints Known: Deadline and budget are understood.
Risks Documented: A preliminary risk list is started.
Dependencies Identified: Known bottlenecks are mapped.
Team Identified: Key players are assigned.
Tip: Before the main kickoff, hold one-on-one “sanity check” conversations with key stakeholders to identify unspoken concerns.
Data Engineering SummaryData Engineering : Step by Step Summary
Extract, Transform, Load (ETL) is a foundational data integration process that consolidates raw data from multiple disparate sources—such as CRM systems, databases, and APIs—into a single, centralized destination, typically a data warehouse or data lake. It is crucial for ensuring that data is clean, consistent, and ready for analytics, BI reporting, and machine learning.
Core ETL Process Steps
Extract: Raw data is pulled from varied sources (structured or unstructured) into an intermediate staging area.
Transform: The staged data is cleaned, formatted, and combined based on business rules to ensure consistency.
Load: The prepared data is moved from the staging area into the final target data warehouse.
Key Benefits
Data Quality & Consistency: Standardizes formats (e.g., date formats, currency) and cleans up errors.
Historical Context: Combines legacy data with new information for long-term analysis.
Automation: Automates recurring data processing tasks, saving time for data engineers.
ETL vs. ELT
ETL (Transform before Loading): Transforms data on a separate processing server before loading, ideal for complex, heavy transformations.
ELT (Load then Transform): Loads raw data directly into the target warehouse (e.g., Snowflake, BigQuery) and transforms it using the warehouse’s power. This is better for large, unstructured datasets.
Detailed Summary
1. Extract
Extraction is the first phase, where raw data is gathered from various heterogeneous sources.
Full Extraction: The entire source is copied; best for small tables.
Incremental Extraction: Only data modified since the last run is extracted.
Update Notification: Source system alerts the ETL tool of a change.
Staging Area: Extracted data is temporarily stored in a “staging area” (or landing zone) to avoid placing heavy loads on production systems during transformation.
2. Transform
This is the most compute-intensive phase, where raw data is converted into a usable format.
Cleansing: Mapping NULL values to 0, removing duplicates, and fixing errors.
Standardization: Converting character sets, date/time formats, or measurement units (e.g., kilograms to pounds).
Data Aggregation: Summarizing data (e.g., total sales per store per day).
Enrichment/Derivation: Creating new calculated values (e.g., calculating profit from revenue and cost).
Encryption/Masking: Anonymizing PII (Personally Identifiable Information) to comply with GDPR/HIPAA regulations.
3. Load
The final phase transfers the cleaned and transformed data into the target destination.
Target Systems: Data warehouses (e.g., Amazon Redshift, Snowflake, Google BigQuery) or Data Lakes.
Loading Methods:
Full Load: Wiping and replacing all data in the target.
Incremental Load: Only loading new/updated data (the “delta”) to the target at regular intervals.
Automation: The process is typically automated to run during off-hours, ensuring the data is ready for morning reports.
Modern Trends and Tools
Cloud-Native ETL: Tools like AWS Glue, Azure Data Factory, and Google Cloud Dataflow allow for serverless, scalable data integration.
Reverse ETL: Moving transformed data from the warehouse back to operational systems (like Salesforce) to activate insights.
Streaming ETL: Processing data in real-time as it arrives, rather than waiting for batch updates, using tools like Apache Kafka.
DataOps: Applying DevOps principles (automation, testing) to data pipelines to ensure reliability and faster deployment.
When to Choose ETL vs. ELT
Choose ETL when: You need to comply with strict data security, perform complex transformations before data hits the warehouse, or have limited computing power in your target database.
Choose ELT when: You are using a cloud warehouse, dealing with massive unstructured data volume, or need high-speed ingestion.
The Campus Serge Kampf Les Fontaines, located in Gouvieux-Chantilly near Paris, is a premier corporate seminar and training center owned by Capgemini. Originally a 19th-century Rothschild estate, it was transformed into a “Campus” for learning, innovation, and reflection, blending historic architecture with modern, sustainable meeting facilities.
Campus Serge Kampf Les Fontaines, in Gouvieux-Chantilly near Paris
Detailed History Timeline
18th Century: Romantic Origins
Late 18th Century: Jacques Berthault acquired a 28-hectare plot, developing a romantic-style garden around a lake, featuring small “follies” (decorative buildings).
19th Century: The Rothschild Era
1878: Baron Nathan James Edouard de Rothschild purchased the estate, increasing it to 52 hectares.
1879–1882: Construction of the Château des Fontaines took place, designed by architect Félix Langlais in an eclectic mix of styles (medieval, 17th-century, Louis XIV). It served as a summer residence and venue for lavish receptions.
20th Century: War and the Jesuits
1931: Baroness Thérèse von Rothschild died, after which the property was passed to her son, Henri.
World War II (1939–1945): Occupied by the German army; utilized by the Luftwaffe as an observation base with a hidden bunker.
1946: The Jesuits acquired the estate to create a cultural and spiritual center, including a vast private library.
1970: The facility was formally established as the Centre Culturel des Fontaines.
Late 20th Century: Acquisition by Capgemini
1997: Facing high maintenance costs, the Jesuits decided to sell the property.
1998: Capgemini bought the estate to create a dedicated international training and seminar campus.
1999–2002: Major redevelopment took place under architects Valode & Pistre to create the campus facilities.
21st Century: The Campus Serge Kampf Les Fontaines
2003–Present: The campus hosts around 275 events annually, serving as a hub for Capgemini University, international meetings, and corporate training.
November 2017: Renamed to “Campus Serge Kampf Les Fontaines” to honor the recently deceased founder of Capgemini.
2020: The lounges of the Château were fully refurbished.
Key Features and Role
Architecture: Combines the historic 19th-century Rothschild château with the “Forum,” a modern, circular 300-room campus building.
Sustainability: Focused on environmental responsibility with a strong commitment to reducing the carbon footprint of events for over 20 years.
Capacity: 50 meeting rooms, including a 500-seat auditorium.
About Serge Kampf
Serge Kampf (1934–2016) was a French entrepreneur who founded Sogeti in 1967, which became Capgemini. He was known for his dedication to client relationships and nurturing entrepreneurial talent.
Campus Serge Kampf Les Fontaines, in Gouvieux-Chantilly near Paris
Capgemini – Campus – Serge Kampf Les Fontaines, Chantilly, France – Advanced EM Course – November 2017 Class